
Java Concurrency - Understanding the Executor Framework And Thread Pool Management
In the previous post, I was writing about the Basics of Threads. This post is going to focus on a higher-level abstraction of thread creation and management.
Concurrent programs generally run a large number of tasks. Creating thread on demand for each task is not a good approach in terms of performance and usage of the resource as the thread creation and threads itself is very expensive. There is also a limitation for the maximum number of threads a program can create, couple of thousands depending on your machine (this is going to be changed with Project Loom).
A call center is one of the good example given to illustrate parallelisation; you can have bounded number of customer representatives in the call center and if there will be more customer calling than your employees, customers wait in the queue until one representative will be available to take the next call. So, hiring a new representative on each call would not make sense.
Therefore it is a better idea to have a thread pool containing a number of threads that would execute the tasks we are sending. Thread pool may create the threads statically (at the time of the creation of the pool), or dynamically (on demand), but it should have a reasonable upper bound. If you like to see a simple thread pool implementation that is queuing the submitted tasks and using the threads from the pool to execute them please check the example in the previous post.
Using the low-level Thread API is also hard and it requires very much attention each time we need to use it. Java Executor framework helps us in this manner by decoupling the creation and management of the Threads from the rest of the application.
In the following sections, I will try to explain consecutively, the ExecutorService interface and its methods, implementations of the ExecutorService, and using the factory methods of Executors to simplify creation of ExecutorService.
The Executor Service
At the heart of the executor framework, there is the Executor interface which has the single execute method:
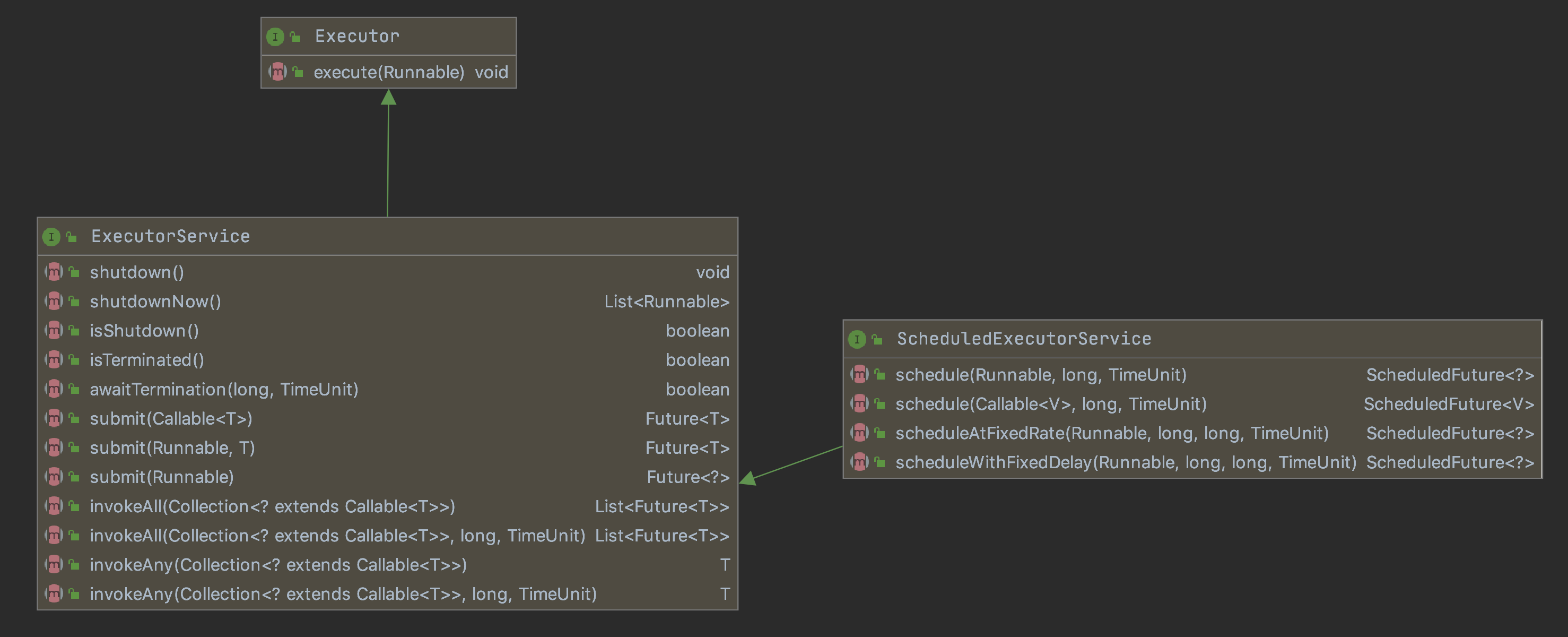
ExecutorService is the main interface extending the Executor and we are going to mostly interact with. It is an abstraction around a Thread Pool, and exposes the submit method that we use to send the tasks. It contains a number of threads in its pool depending its implementations which we will see in the following sections.
When we send the Runnable or Callable tasks by submit method, the threads from the pool are going to run them.
- Runnable: So far we have mentioned only about runnable, which does not return anything or is not able to throw any exception.
- Callable: As similar to the Runnable, designed for classes whose
instances are potentially executed by another thread, but returns a result and may throw exception.

Submit method returns a Future object that represents the result of an asynchronous computation. Future has methods to check if the task is complete, to wait for its completion, and to retrieve the result. Its get method returns the result but it is a blocking method, so we can postpone calling the get method as long as possible and do other operations. Once we need the result of the task, we call the get method and if the result is not ready the calling thread will be blocked and we need to wait the result. If we can not afford waiting for long time, we can call the method with a timeout.
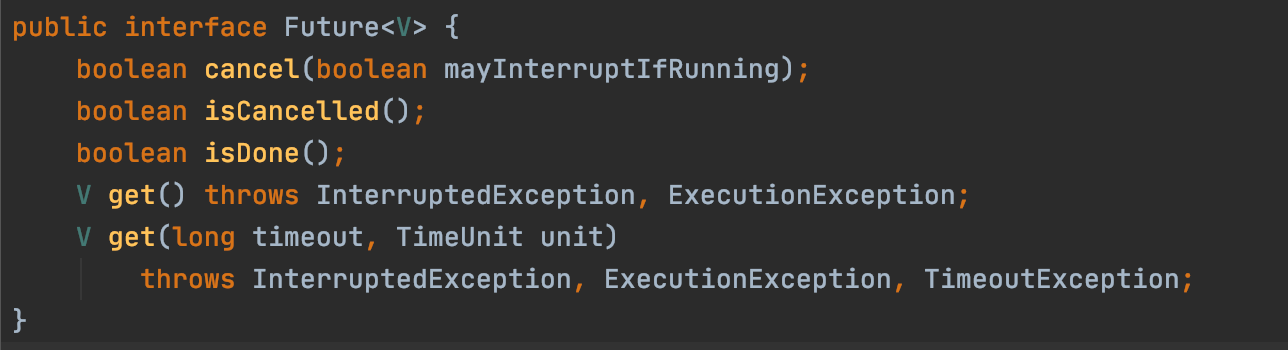
The ExecutorService also provides methods for sending collection of tasks all together. We can use invokeAll method to send multiple tasks, and it returns List of Futures. InvokeAny method can be used to run similar tasks, and it returns the fastest answer
Another important advantage executor service provides is that it has shutdown functionality to stop the pool and the threads. There is an important difference between shutdown and shutdownNow methods:
- shutdown: Calling this method indicates that no new tasks will be accepted to the queue, and previously sent tasks are going to be waited to complete. Note that if the tasks are long running tasks (infinite loop) they will never complete.
- shutdownNow: This method interrupts all the active threads, stops the processing of new tasks from the queue and returns the list of those tasks that were waiting in the queue.
Note that in order to stop the processing, we need to handle the interruption in our Runnable/Callable tasks. Otherwise shutdownNow will trigger interruption but no thread will show reaction to it, and it behaves same as shutdown.
We can also see the ScheduledExecutorService in the first diagram, as it extends the ExecutorService and provides methods to run scheduled tasks. It is an high-level abstraction for the Timer, and it is easier and better way to run periodic tasks.
Implementations of the ExecutorService
ExecutorService instances are mostly created by using Executors factory methods, and I will show it in the next section. Executors factory methods are easy way to generate Thread Pools, however before using that, I would like to show the important concrete classes that implements the ExecutorService, because the factory method internally retrieves one of these implementations, and I believe it is important to understand the internals. Knowing some of the concrete ExecutorServices, we can create custom pools in case we have specific needs.
If we look at the following diagram, we have AbstractExecutorService which provides default implementations of submit, invokeAny and InvokeAll methods of the ExecutorService. Concrete implementations overrides some of the implementation details.

1- ThreadPoolExecutor
The ThreadPoolExecutor is a one of the core implementation of the ExecutorService and it executes each submitted task using one of possibly several pooled threads. This class provides many adjustable parameters and extensibility for configuring and managing the pool. We can configure the following parameters in this class:
- corePoolSize: minimum number of Threads in the pool.
- maximumPoolSize: it is self explanatory, the upper bound of pool size. By setting the
corePoolSizeandmaximumPoolSizethe same number, we simple create a fixed size pool. - ThreadFactory: New threads are created by using a
ThreadFactorywhich is by defaultExecutors#defaultThreadFactorythat creates threads to all be in the sameThreadGroup, with the samepriorityandnon-daemonstatus. If you like to customise it, you can set a differentThreadFactory. - keepAliveTime: When the pool has more than minumum number and the threads are idle, exceeding ones are terminated after the
keepAliveTime. - Queue: A
BlockingQueuecan be configured to keep the submitted tasks. Example queues and the queueing strategies are as follows:
SynchronousQueue: It is provides a direct handoff strategy, which means that tasks are delivered directly to the workers without storing them in a queue. If no threads are available to take the received task, then a new thread will be constructed. If a maximumPoolSize is set and that limit is reached, task will be rejected.LinkedBlockingQueue: It provides unbounded queue strategy which means, using a queue without a predefined capacity. This will cause new tasks to wait in the queue when all corePoolSize threads are busy. So no more than corePoolSize threads will be created and the value of maximumPoolSize does not have any effect.ArrayBlockingQueue: It provides bounded queue strategy which means, using a queue with a predefined capacity. It has a limited space in its queue therefore there should be enough number of threads to consume the tasks rapidly. When the queue is not full tasks are added to the queue. When queue becomes full, and the number of threads are less than maximumPoolSize a new thread is created. Finally when number of threads reaches the limit, the task is rejected.
We can configure parameters mentioned above at the construction time or later with the setter methods.
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
Example of running multiple tasks by ThreadPoolExecutor:
public class Main {
private static final int CORE_POOL_SIZE = 4;
private static final int MAX_POOL_SIZE = 4;
private static final AtomicInteger taskCounter = new AtomicInteger(0);
private static final ThreadFactory threadFactory = (runnable) -> new Thread(runnable,
"thread " + taskCounter.incrementAndGet()); // name each thread
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor pool = new ThreadPoolExecutor(CORE_POOL_SIZE,
MAX_POOL_SIZE,
0L, // No timeout.
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(),
threadFactory);
Collection<Callable<Long>> tasks = new ArrayList<>();
for (int i = 0; i < 10; i++) {
int var = i;
tasks.add(() -> {
System.out.println("[" + Thread.currentThread().getName() + "]"
+ " running the task: " + var);
return Long.valueOf(var * var);
});
}
List<Future<Long>> futures = pool.invokeAll(tasks);
futures.forEach(longFuture -> {
try {
Long result = longFuture.get();
System.out.println("Result: " + result);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
pool.shutdown();
pool.awaitTermination(1, TimeUnit.SECONDS);
}
}It would give the following result:
[thread 4] running the task: 3
[thread 2] running the task: 1
[thread 3] running the task: 2
[thread 1] running the task: 0
[thread 4] running the task: 4
[thread 2] running the task: 5
[thread 1] running the task: 6
[thread 2] running the task: 7
[thread 1] running the task: 8
[thread 2] running the task: 9
Result: 0
Result: 1
Result: 4
Result: 9
Result: 16
Result: 25
Result: 36
Result: 49
Result: 64
Result: 81As you can see in the UML diagram, apart from its configuration, ThreadPoolExecutor class provides many more useful methods, related to the queue, tasks or threads. So it is obviously more verbose than having an Executor, or ExecutorService instance to interact with the pool.
2- ForkJoinPool
The fork/join framework is designed to recursively split a parallelizable task into smaller tasks and then combine the results of each subtask to produce the overall result. The way it works is quite different than the other ExecutorServices, as it is build upon an algorithm based on Divide and Conquer.
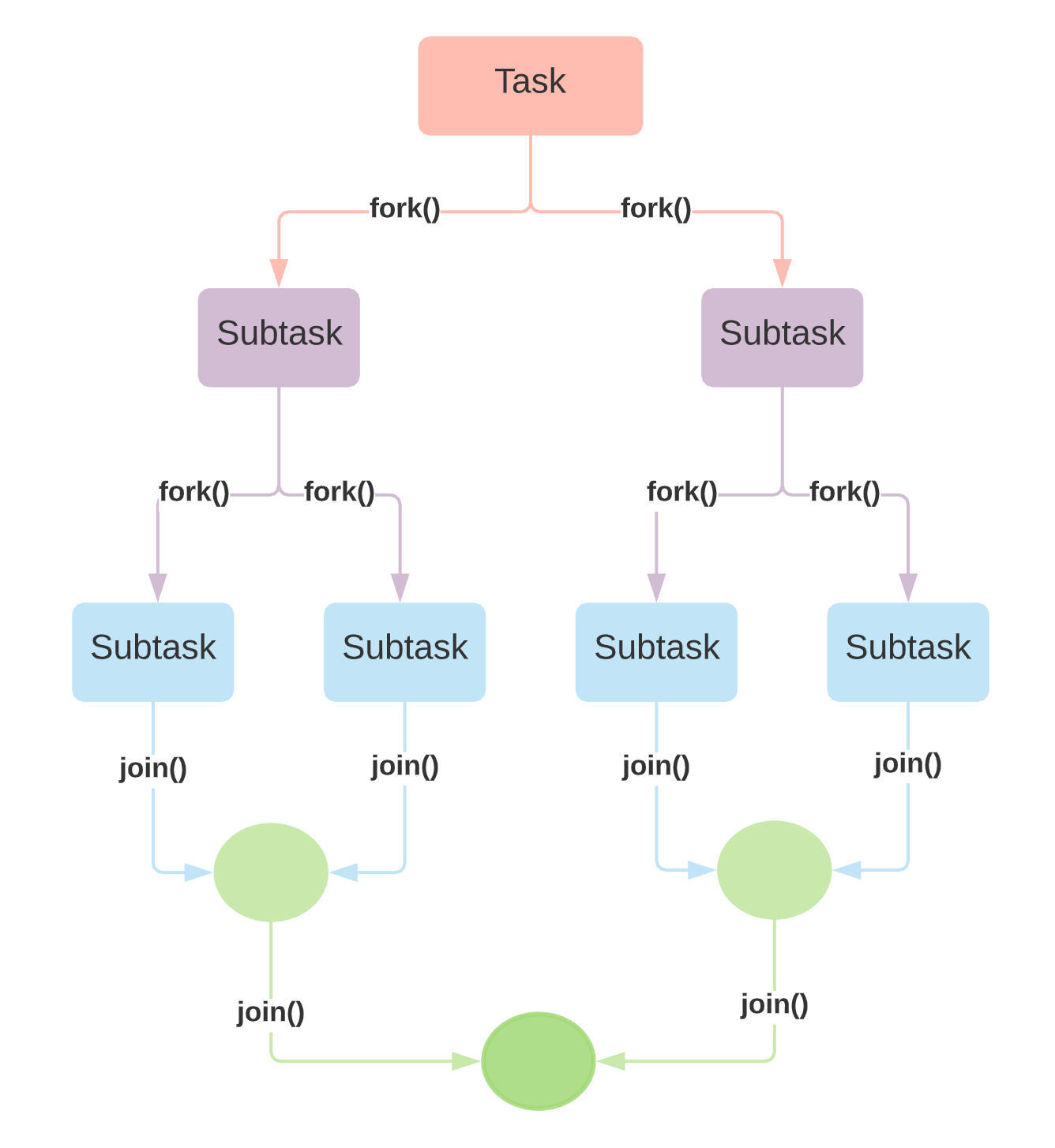
As it can be seen in the above figure tasks should be divided into smaller tasks, each small task should be run separately and the results should be combined and merged. When the tasks does not have dependencies to each other and can be divided into smaller subtasks this framework can be used to process them in parallel.
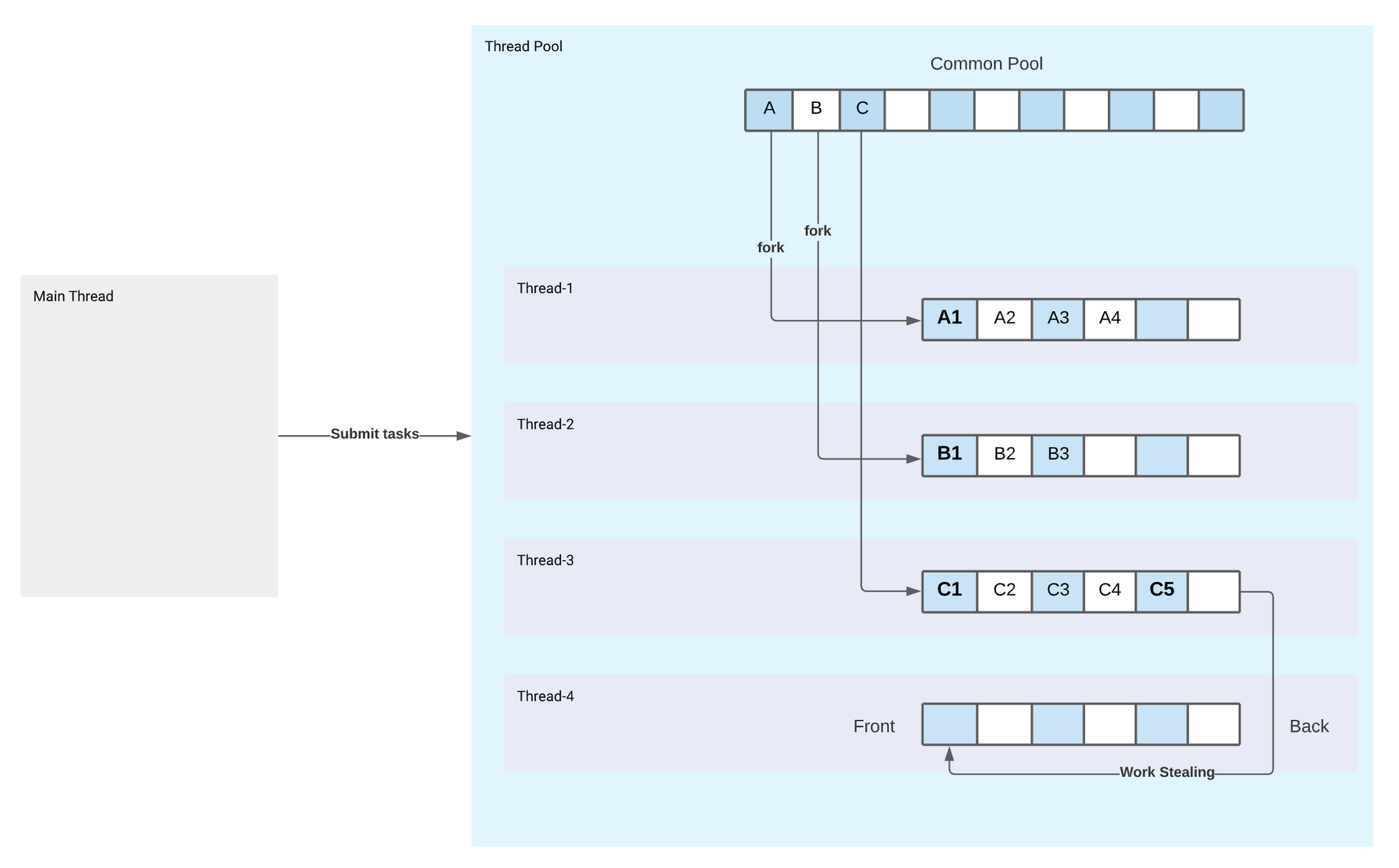
ForkJoinPool contains a single common queue that contains the tasks that are sent form outside, and fixed number of worker threads. Each thread also contains a deque (Double ended queue). Once a thread takes a task from queue, the tasks is divided into smaller pieces and thread add the these smaller subtasks into its deque. The treads takes the subtasks from the front of the deque and processes. Therefore each thread contains the subtasks in its own queue. Once a thread does not have anymore a task in its deque, and also there are no more tasks waiting in the common queue, it starts to take tasks from the back of other threads deques. This behaviour is called work stealing. By this way, ForkJoin framework maximises the efficiency of each thread, decreases the competition between the threads to take task and provides improved parallelism.
In order to work with ForkJoin Framework API in Java, we need to create RecursiveTask instances which is used to define how to operate, divide etc. The API details is not going to be covered in this post.
ForkJoin Framework is used in many places in java, such as in ExecutorServices as we have seen, in parallel streams, in CompletableFutures and so on. Especially Streams API heavily uses ForkJoin pools, so it is important to understand how it works and how it is integrated with streams.
3- ScheduledThreadPoolExecutor
This executor is used to run the task once or periodically multiple times in the future. It serves the similar purpose with Timer class, but it is higher level implementation. After creating an instance, we can simple use the one of the schedule methods:
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);An example logging task can be implemented as follows:
public static void main(String[] args) {
Runnable runnable = () -> {
System.out.println("[" + Thread.currentThread().getName() + "]"
+ " running the scheduled task");
};
ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(1);
executor.scheduleAtFixedRate(runnable, 1, 1, TimeUnit.SECONDS);
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
executor.shutdown();
try {
executor.awaitTermination(1, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}));
}Executors Factory Methods
In the previous section we have seen the concrete implementations of ExecutorServices. It is good to know the way to create, configure and manage them. However, we can easily generate ExecutorServices by calling the static factory methods of the Executors class. The class provides the following methods to help creation of thread pools:
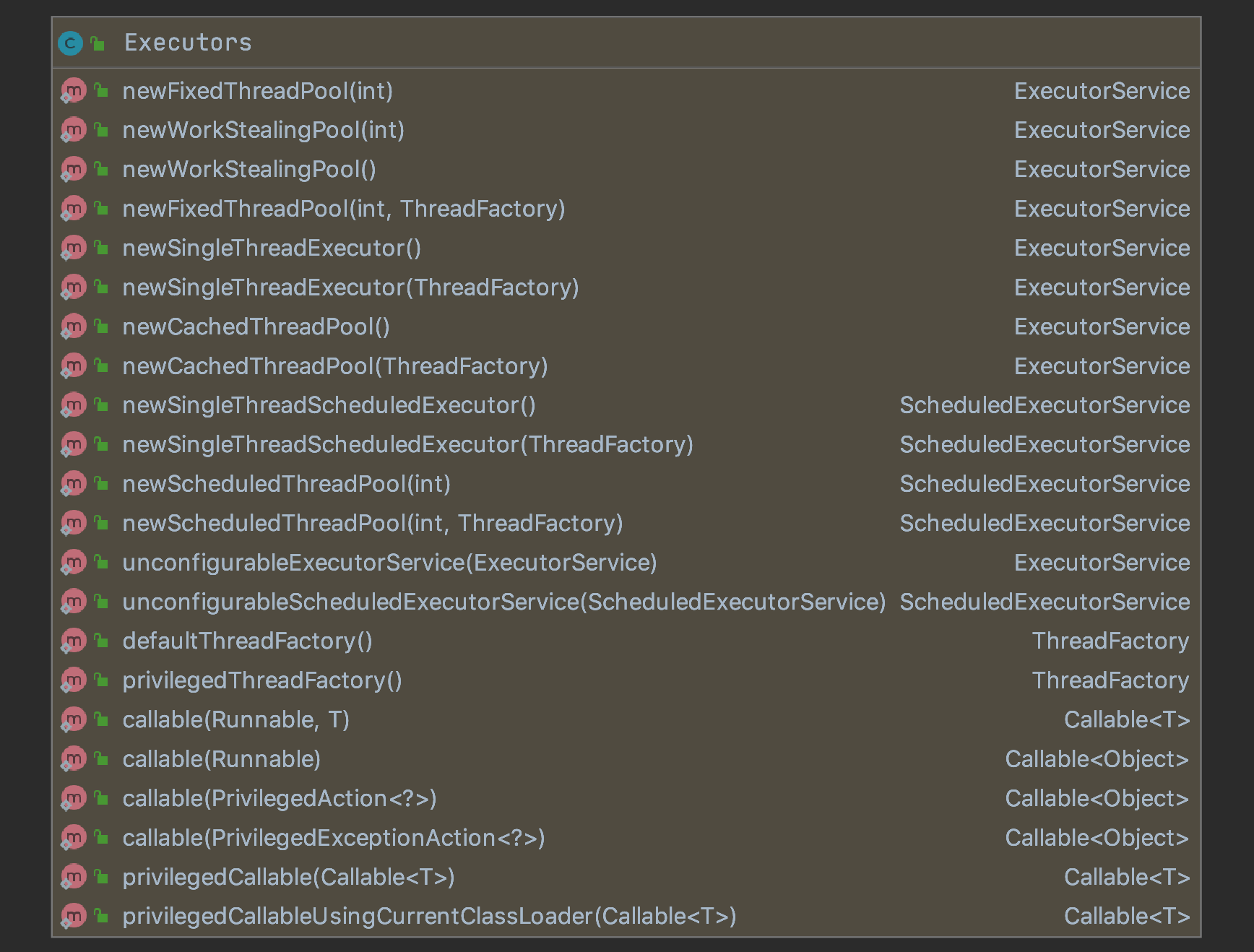
So we can create most of the commonly used thread pools:
ExecutorService fixedPool = Executors.newFixedThreadPool(4);
ExecutorService workStealingPool = Executors.newWorkStealingPool();
ExecutorService singleThreadPool = Executors.newSingleThreadExecutor();
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
ScheduledExecutorService scheduledPool = Executors.newScheduledThreadPool(1);Executors class provides convenient and easy way to generate pools, and generally that's how we create them rather than using the new keyword and initiating the ExecutorService types. As mentioned before Executors class uses the concrete implementations of ExecutorService interface to generate these pools with reasonable default configurations. As a matter of fact, if we inline the method calls we can see the the details how they are being generated:
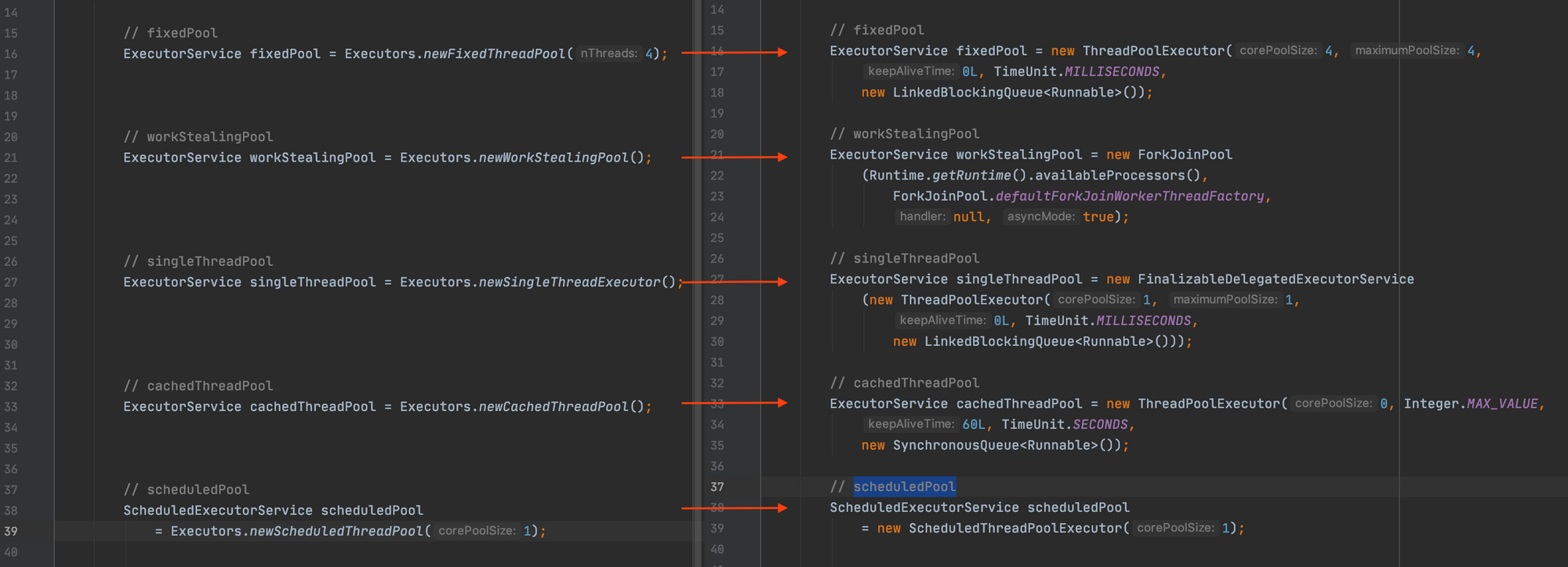
Gracefully closing the Executor Services
We need to remember to close the thread pools when we are done with them, in order to free the resources and also to not cause any problem. If we forget to close, the main process will not exit and hang as long as pool exists. If we need the pool for very specific purpose, we can immediately close them after using. However generally the common approach to have a the thread pools is keeping it in a Singleton class, so pools lives as long as the program is running, and does its job during its lifetime. In such cases we can add a shutdown hook in order to close the pool right before JVM exits.
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
executor.shutdown();
try {
executor.awaitTermination(1, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
}));
