Apache Kafka Basics Made Simple
Apache Kafka is a publish/subscribe messaging system. It is also described as distributed streaming platform. Why may we need such a system? We need to first understand the reasoning behind the publish/subscribe systems. Applications can communicate with each other and share data by APIs, Remote Procedure Calls, etc. But things may get complicated, when the number of processes that needs to communicate increases, such as:
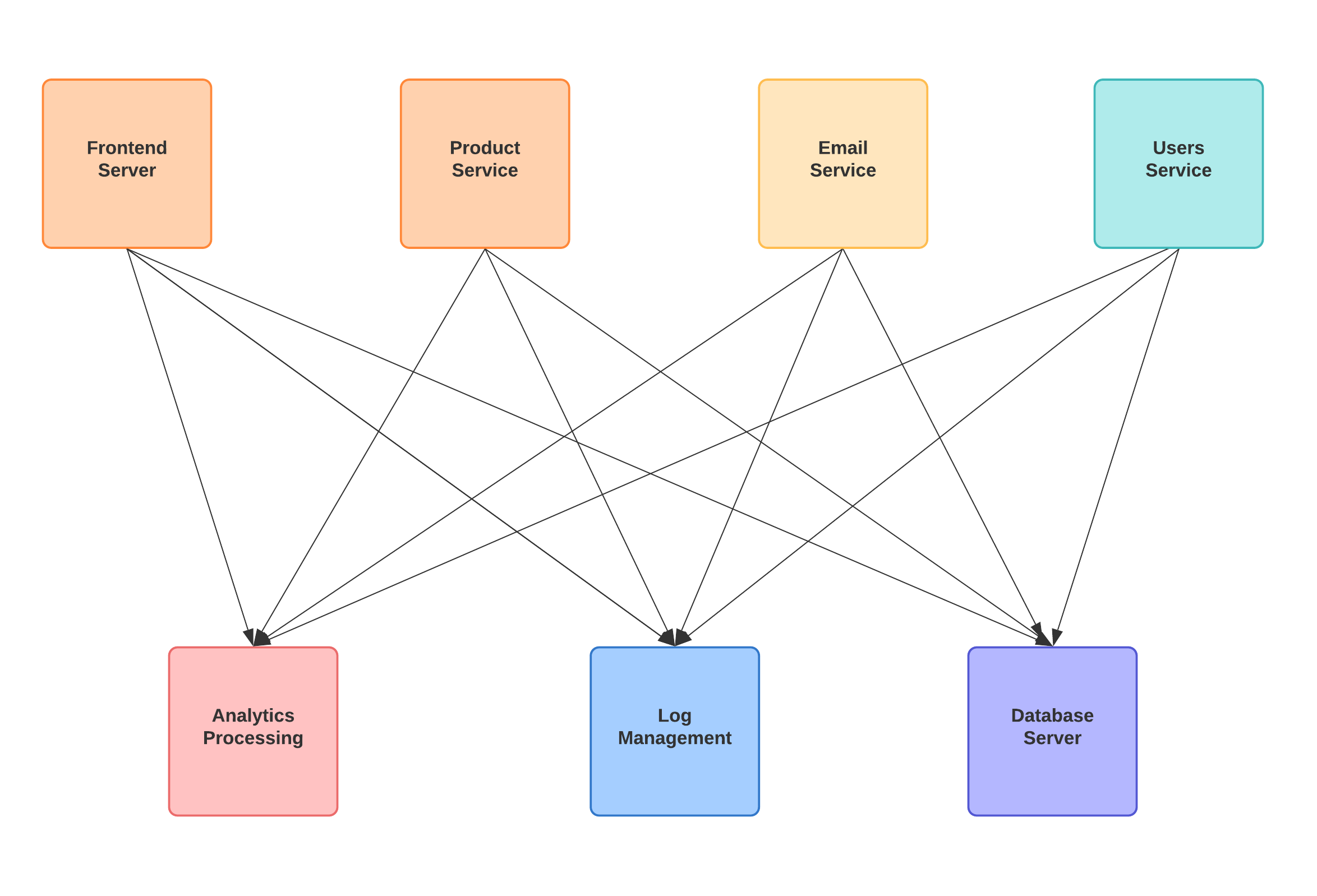
Connections becomes hard to implement, manage and trace. If we have N source system and M target system, we should implement N x M integration. Each integration comes with its difficulties:
- Protocol to be used (TCP, HTTP, REST, FTP, JDBC...)
- Data format to parse the message (Binary, JSON, CSV...)
- Data schema and its evolution
- Extra load from the connections
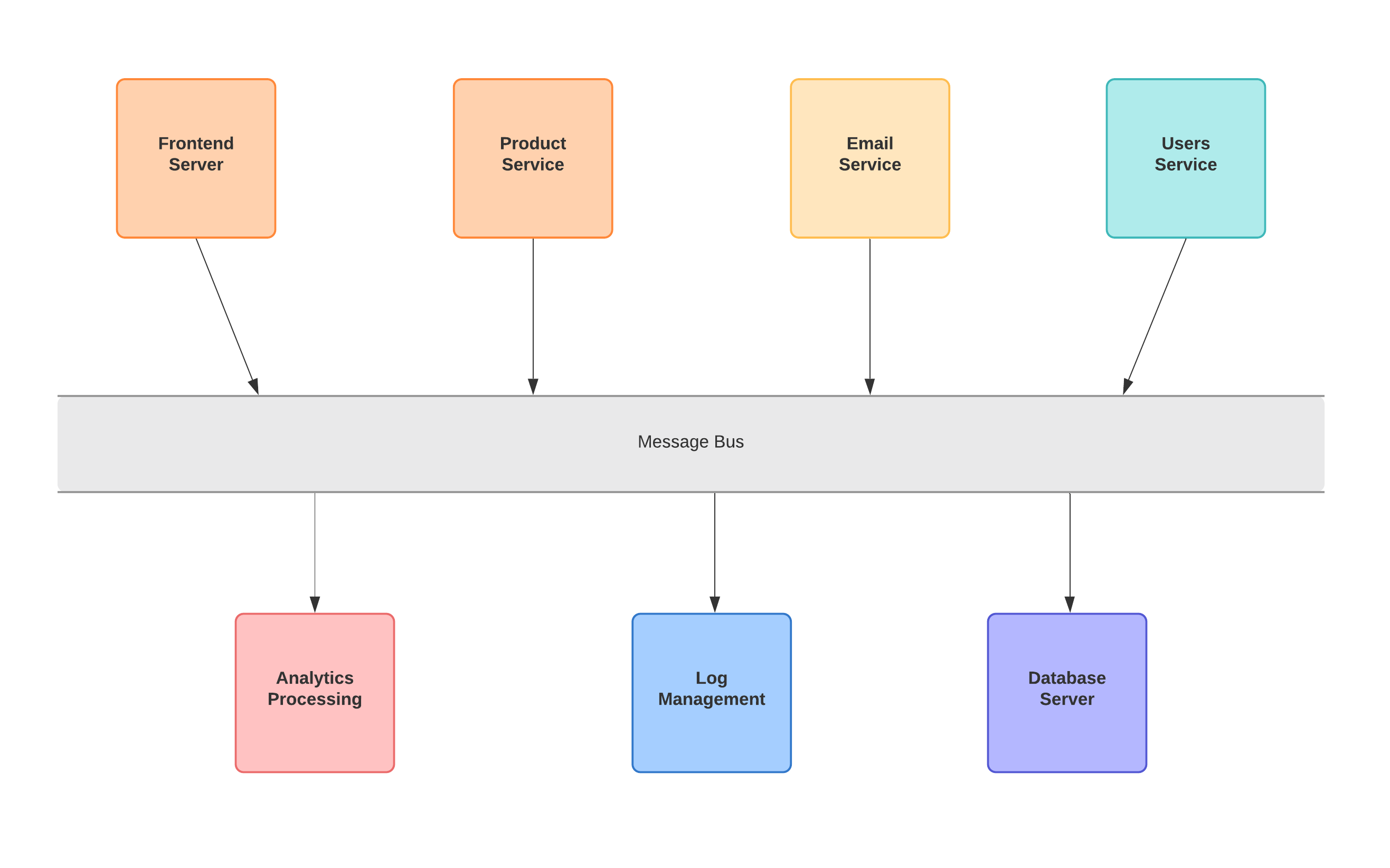
In such a case it is better idea to decouple the applications from each other. Message queues comes into play at this point to let the applications talk to each other asynchronously. So for example if I want to pass an information to my colleague I would send an email, it is delivered to his inbox and he reacts the message when he is available.
In Publish/subscribe pattern consists of a sender (Producer) which sends the data (Message) to the message queue (Broker), and a receiver (Consumer) that listens the messages from the queue. So our complex communication flow becomes:
Apache Kafka is simply a distributed publish/subscribe messaging queue. In fact its capabilities are far beyond then that.
Features
- Multiple Producer and Multiple Consumer
- Disk-Based Retention (Messages are stored)
- Scalable (Multiple brokers)
- Resilient Architecture
- Fault tolerant (Commit log mechanism)
- High Performance (Latency of less than 10ms)
Use Cases
- Activity tracking (Page views, click tracking, entity update...)
- Messaging system (Notifications)
- Gathering metrics (Monitoring and alerting)
- Gathering logs (Monitoring and alerting)
- Commit log (Gather database changes to Kafka)
- Stream processing (Transform/Process the data)
- Decoupling system dependencies
- Integrating with other data technologies (Hadoop, Spark, Storm, PostgreSQL...)
Kafka Concepts
Messages
The unit of data within Kafka. Similar to a record or a row in database table. It is stored simply as an array of bytes in Kafka. Messages may have an optional key parameter. Note that Kafka stores our messages for some period of time but not forever, they are deleted according to retention policy. Messages are written to Kafka in batches for efficiency.
Schema
While messages are stored as byte arrays, they do not have any meaning for Kafka. We can impose a structure, or schema on the message content to help Kafka understand the message structure. For example JSON or XML is easy to use and human readable but they lack the type handling and compatibility between schema versions. Apache Avro is recommended framework for serialising the messages and managing schema changes.
Topics
Topics are particular stream of data. As single topic represents a single stream of data moving from the producers to the consumers. Messages are categorised into topics and topics are identified by its name. Similar to a table in a database. You can have as many topic as you like. Topics are divided to partitions and typically have multiple partitions. At the time of creating a topic in Kafka, we need to specify the number of partitions.
Partitions
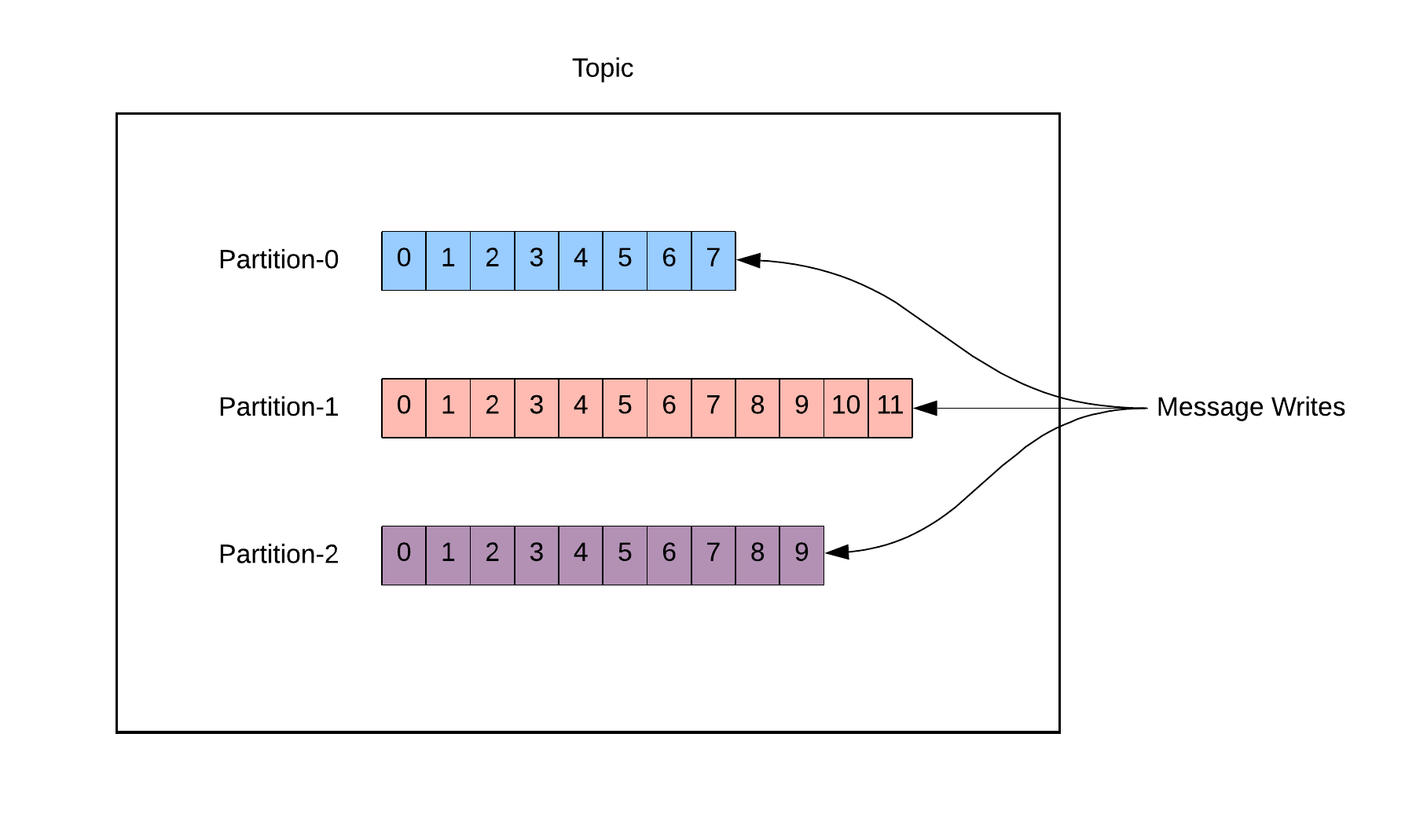
Each partition is an ordered immutable sequence of messages that is continually appended. So messages are written in the order they are received and we can not update them after they are inserted to partition. We can think of partition as a single log in the commit log mechanism. Each message within a partition gets an incremental id, called offset. Data is written to a random partition unless a key is provided.
Dividing a topic into multiple partitions is needed to provide distribution between different servers. Each partition can be handled by different servers, so a single topic can be scaled across multiple servers. Therefore Partitions are also the way that Kafka provides redundancy and scalability.
Note that message-time ordering is guaranteed only within partitions not for the entire topic. So in the following diagram, it is guaranteed that the data in the Partition-0 is ordered, timestamp of Offset-0 is smaller than the Offset-1's timestamp.
Brokers
Broker is a server that holds the topics or partitions of some topics. Kafka cluster consist of multiple brokers. So a cluster is multiple machines and broker is a single server. Brokers are identified by their IDs. As we can see in the following diagram each broker contains certain topic partitions.
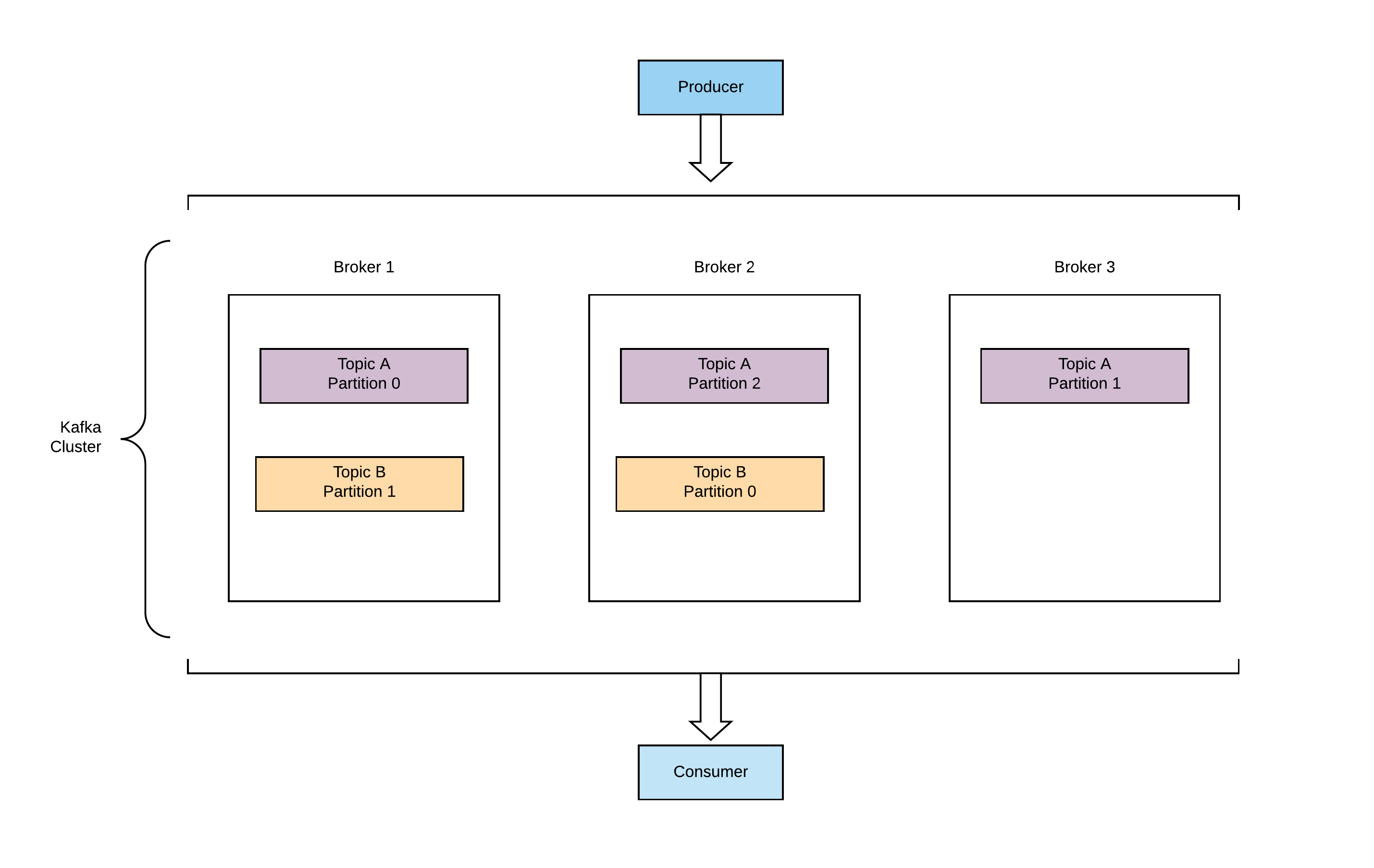
Kafka Clients
Kafka clients can be separated as consumers, producers. There are also other advanced clients (Kafka to Kafka flow) such as connectors or streams that uses client APIs.
Producers
Producers simply sends message to a specific Kafka topic. They do not have to specify the partition to be written, but also they can choose the partition for a message by assigning message key. Well, in fact, it is not literally choosing partition number but Kafka assures that all messages produced with a specific key will get written to the same partition. This is guaranteed as long as the number of partitions remains constant. If a new partition is added on demand, the hashing will change.
If we need ordering for our entities we can use entity id as a key and we make sure that messages for same entity will be always in the same partition, therefore ordered. Keys can be chosen as strings, integers, etc. If message is sent without key, partition will be chosen with round robin.
Producers can require to get Ack from broker to approve that message is saved.
Ack=0: no ackAck=1: only leaderAck=all: all copies
Consumers
Consumers read messages from a specific Kafka topic. They can also subscribe to multiple topics. Consumer knows which broker to read from.
Delivery semantics: They keep track of the messages that they consumed by offsets. The offset of the last consumed message for each partition is, in fact, stored in a Kafka topic which is named as __consumer_offsets so that if a consumer dies and turns back again it can continue its work from where it was left off. After reading some messages, consumer commits the last read offset to this topic, to save its place. They choose when to commit the offset, and there are 3 delivery semantics for that purpose:
At Most Once: committed as soon as message is received by consumer. If the processing goes wrong, it wont be read again as the message is already signed as read.At Least Once: committed after the message is processed. If processing goes wrong it will be read again. This can cause duplicate processing of a message. So it can be used for idempotent systems (processing the same message again will not impact the system)Exactly Once: Kafka does not support this delivery mechanism for external systems. It can be only used Kafka to Kafka systems.
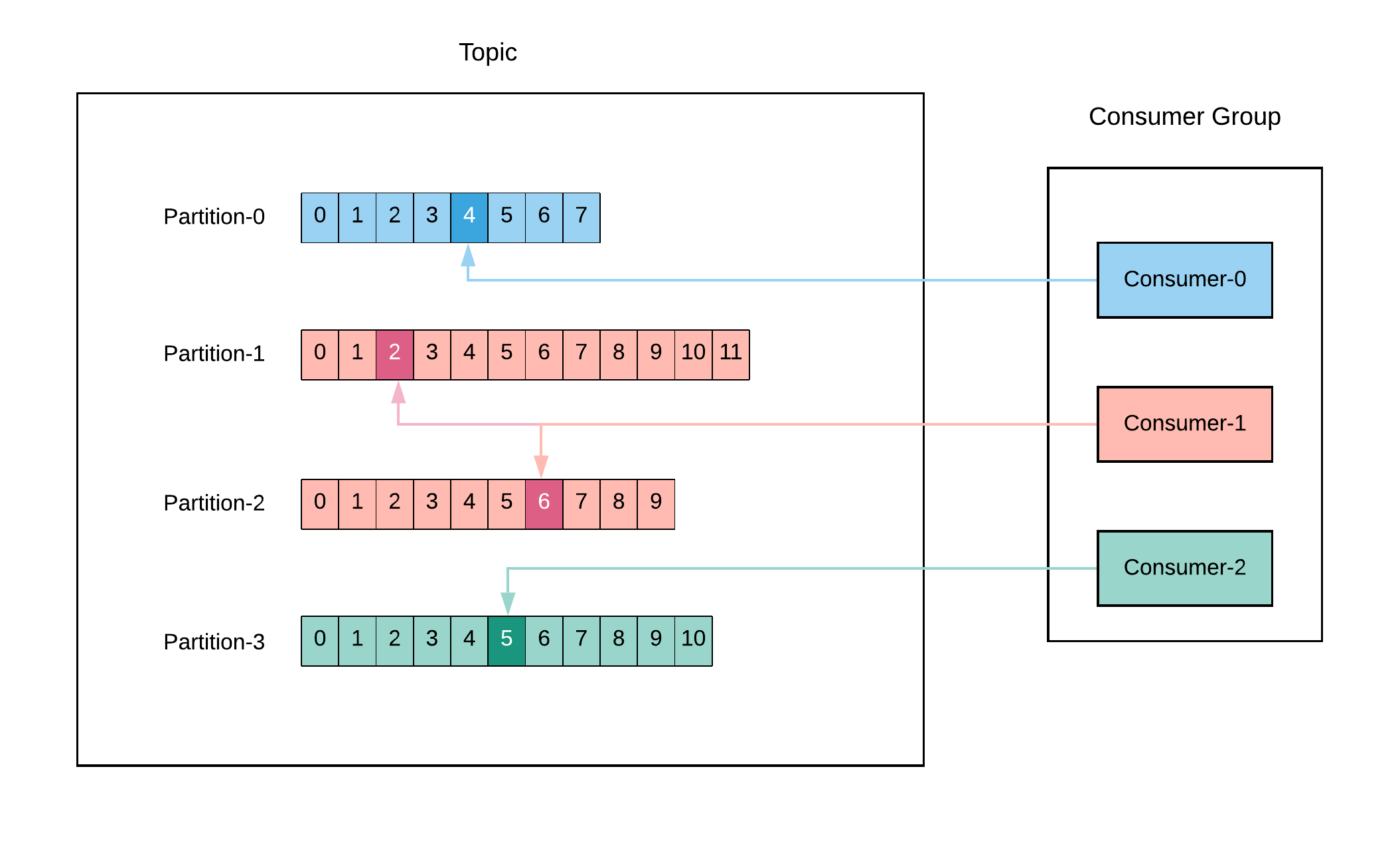
Consumer Groups: Consumer is a single worker within a consumer group that is subscribed to a topic. In the group each partition is assigned to a single member (ownership). In the following figure, consumer partition mapping is as listed:
Consumer-0->Partition-0Consumer-1->Partition-1,Partition-2Consumer-2->Partition-3
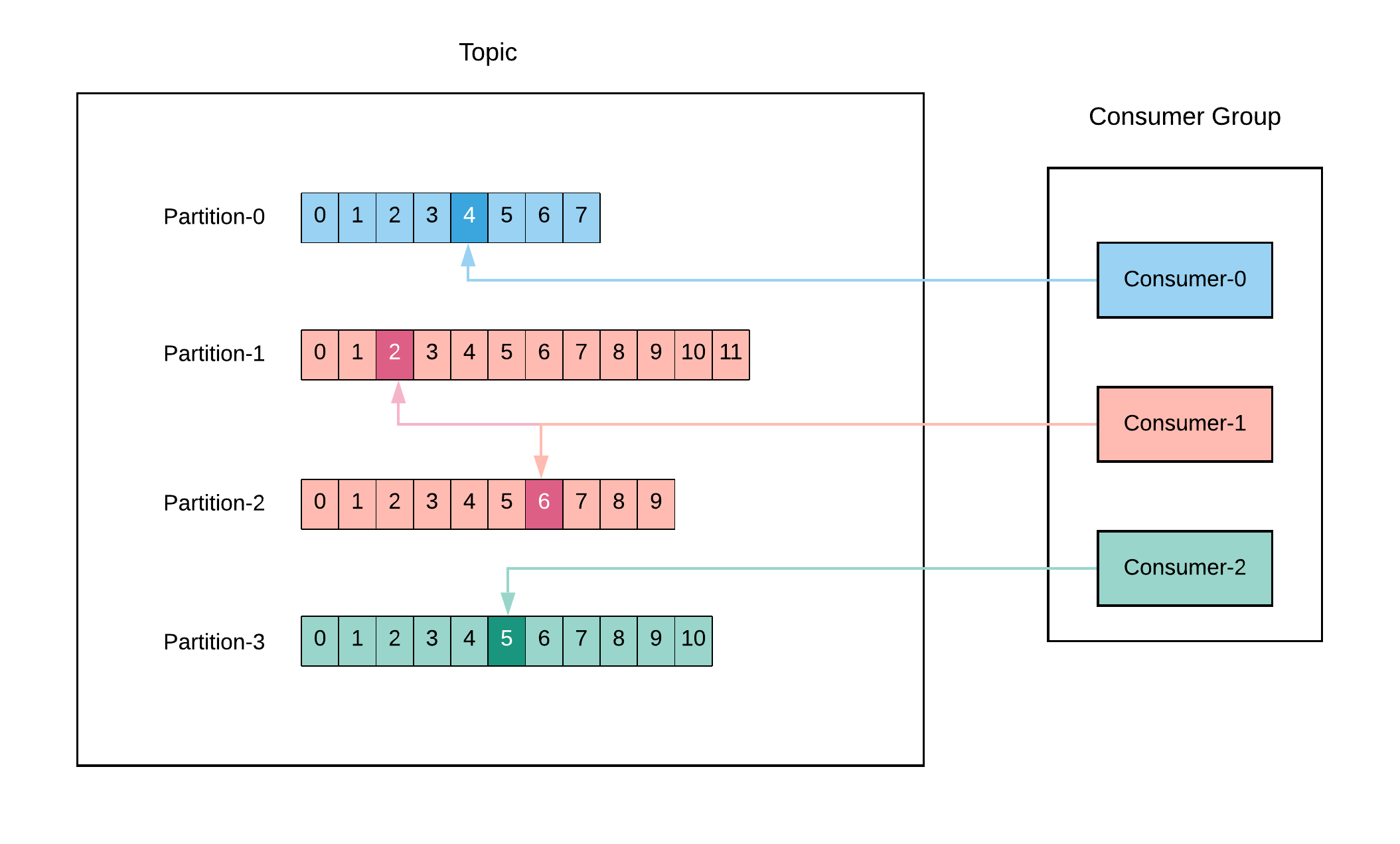
This mapping provides us that we can scale the consumers (add new consumers to the group) for a large topic to increase the performance. Also if a consumer fails, the remaining members of the group will rebalance the partitions to take over. What's more we can deduct from this mapping is that if we have more consumer than partitions, then some consumers will be idle, for instance if we have 3 partitions and 4 consumers, 1 will be inactive as 3 partitions will be assigned to remain consumers.
See another consumer group example in the following figure.
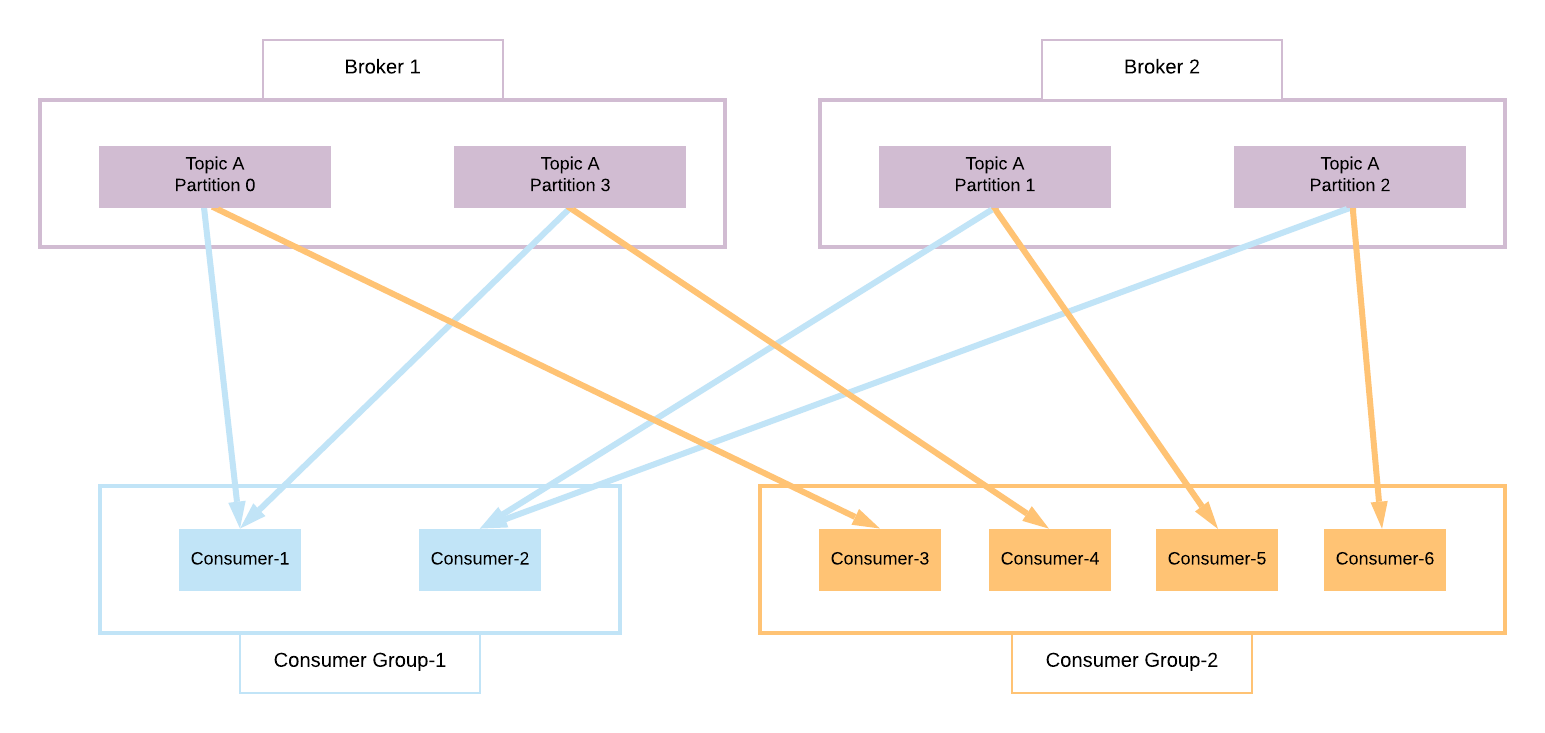
We have a topic A, with 4 partitions split into 2 brokers. We have 2 different consumer groups. First one's consumer-partitions ownership is as follows:
C1->P0,P3C2->P1,P2
In the second consumer group each consumer read from one partition assigned:
P0->C3P3->C4P1->C5P2->C6
Replication Factor
Replication factor means number of the copies for each partition. Each copy is located in a different broker. By this way if one broker is down another broker can serve the data. Topics ideally should have replication factor bigger than 1.
Among the copies, 1 broker is selected as leader of the partition. Other copies are called passive replicas. Only the leader can receive or serve data for a partition. Other brokers get synchronised the data. These passive replicas are also known as In-Sync Replica (ISR).
Therefore 1 partition is stored in 1 leader and multiple ISR brokers. Leader selection is handle by Zookeper which is used as a manager by distributed systems as Kafka. If the leader goes down, then one of the ISR is elected as a new leader.
See the following example, we. have the topic A, with 2 partitions that both have replication factor of 3, and having 3 brokers in the cluster. Leader and replica partitions are distributed as follows:
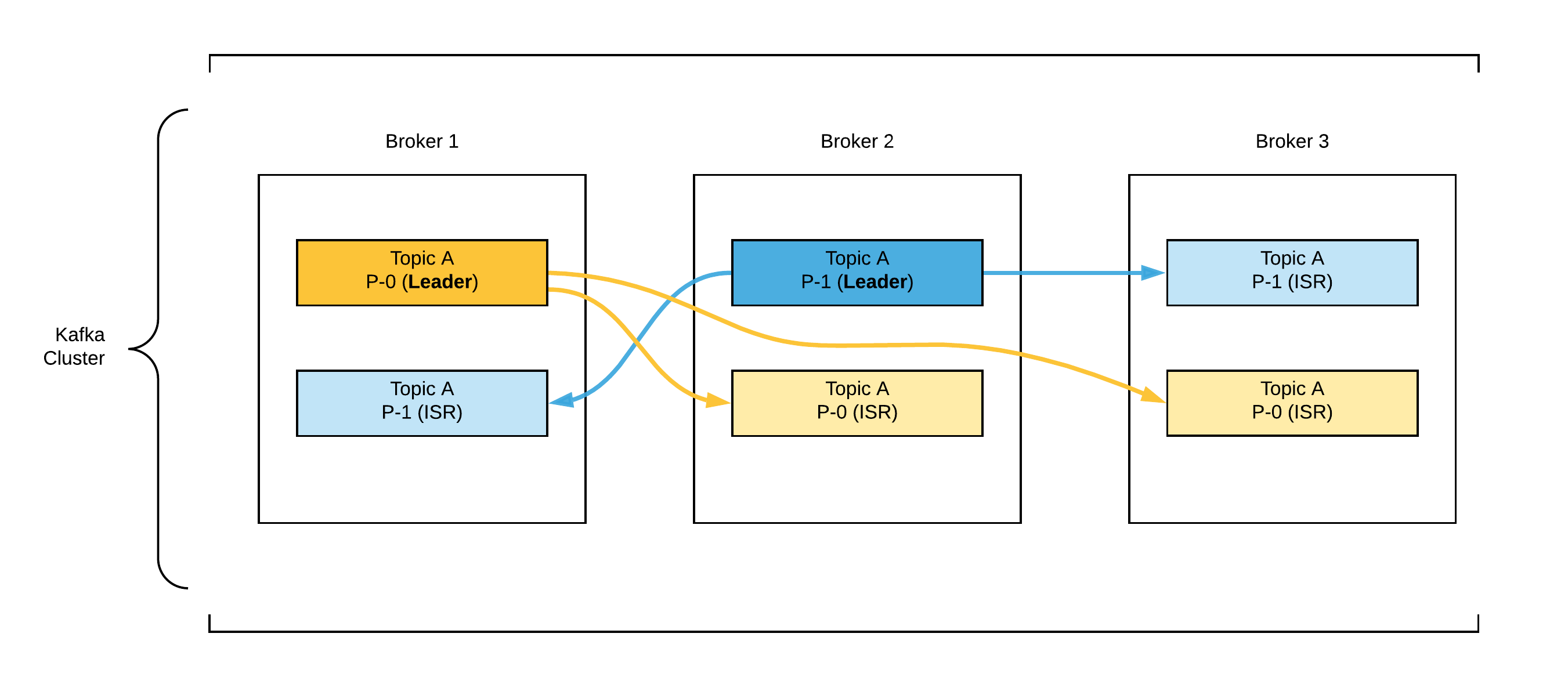
In this example even if the connection of 2 brokers are lost, our data will be still accessible. So replication factor provides N-1 fault tolerance. It is a good practice to set it minimum 3.
Kafka Broker Discovery
Every Kafka broker is called as a Bootstrap Server. A broker knows all the brokers, topics, partitions etc. in the entire cluster. It means that when we connect to a single broker in a cluster, then we receive information about the entire cluster and we can connected to entire cluster.
Zookeeper
Zookeeper manages the brokers, keeps list of them. It helps for leader election for partitions. It sends information to Kafka about changes in the cluster, such as new topic created, broker is not accessible, broker joined, delete topic, etc. So all the metadata of the Kafka cluster is managed in Zookeeper.
Although there is a proposal and work in progress for removing the Zookeper necessity from Kafka at the time of writing it is the dependency in order to run a Kafka cluster.
References
Narkhede, N., Shapira, G., & Palino, T. (2017). Kafka: The definitive guide: Real-time data and stream processing at scale. Sebastopol, CA: O'Reilly Media.

