
Apache Kafka Advanced Producers
Apacke kafka has kafka-clients library which contains built-in client APIs that developers can use when developing applications that interact with Kafka. Library contains the consumer and producer APIs.
Our point of interest in this post is the generic KafkaProducer<K, V> class that publishes records to the Kafka cluster. I will show a basic implementation of a kafka producer and then discuss the details of configurations. If you would like to check Apache Kafka basics, refer to the post: Apache Kafka Basics.
Basic Kafka Producer Implementation
- Add
kafka-clientsDependency:
compile 'org.apache.kafka:kafka-clients:2.5.0'- Create Properties
KafkaProducer<K, V> class needs a Properties object to be able to create a new instance. So we can create a Java Properties object and add the obligatory configuration properties.
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());- Create Producer
With using our properties we can initiate our producer. We need to specify the types of Key and Value to the generic KafkaProducer class. Simply we can use String keys and values if messages does not have a schema.
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);- Create Producer Record
Each message that we are going to send should be wrapped with ProducerRecord<K, V> instance. This generic class also needs us to specify the type of Key and Value.
ProducerRecord<String, String> record = new ProducerRecord<String, String>("topic", "key", "value");- Send Message
send method has 2 implementations:
Future<RecordMetadata> send(ProducerRecord<K, V> record);
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);So we can either send the record directly:
producer.send(record);Or add a callback method:
producer.send(record, (metadata, exception) -> {
if (exception == null) {
logger.info("Message sent: {}", metadata.toString());
} else {
logger.error("Message failed with exception: {}", exception.getMessage());
}
});- Close the producer instance and flush data
Remember closing the producer gracefully when you no longer need or application exits. Failure to close the producer will leak the resources that it is using.
producer.flush();
producer.close();Putting pieces together
So I can wrap all the steps with a custom singleton class that will accept topic, key, value to be sent.
public class Producer {
private static final Logger logger = LoggerFactory.getLogger(Producer.class);
private static Producer instance = null;
private static KafkaProducer<String, String> producer;
private Producer(Properties properties) {
producer = new KafkaProducer <>(properties);
}
public static Producer getInstance() {
if (instance == null) {
instance = new Producer(getDefaultProperties());
}
return instance;
}
private static Properties getDefaultProperties() {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
return properties;
}
public Future <RecordMetadata> sendRecord(String topic, String key, String value) {
ProducerRecord<String, String> record = new ProducerRecord <>(topic, key, value);
return producer.send(record, handleResult());
}
private Callback handleResult() {
return (metadata, exception) -> {
if (exception == null) {
logger.info("Message sent: {}", metadata.toString());
} else {
logger.error("Message failed with exception: {}", exception.getMessage());
}
};
}
public void close() {
producer.flush();
producer.close();
}
}So we are able to send messages. But how the KafkaProducer works. Let see behind the scenes.
Overview of Kafka Producer
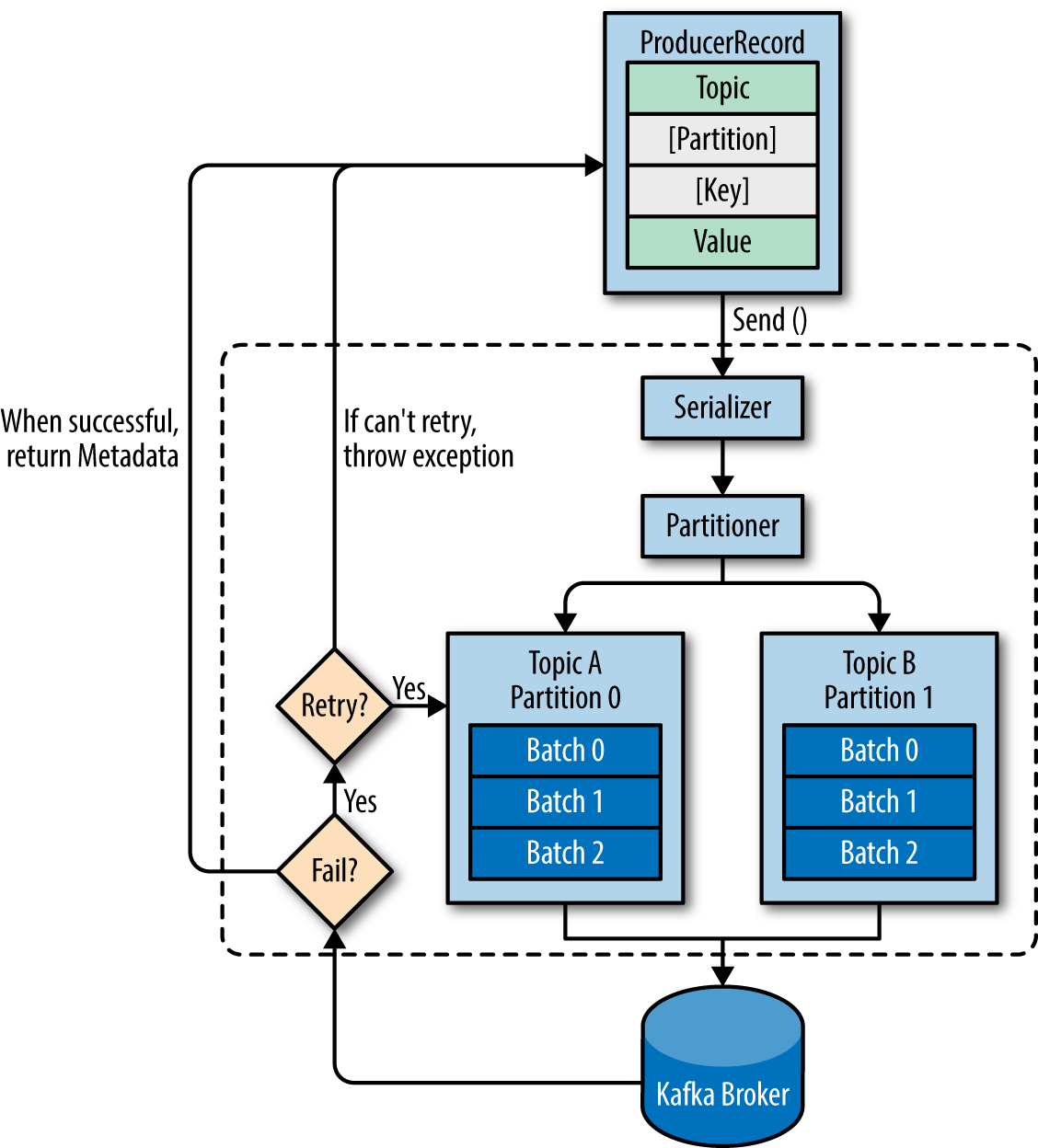
- Kafka Producer is thread safe. Intended to be shared by multiple threads to publish faster and with higher throughput.
- Messages are instance of
ProducerRecordwhich contains the topic and the value of message. (key is optional) send()method is asynchronous. It pushes the records to buffer and returns immediately with aFutureobject. So if we call thegetmethod of future, it blocks the caller and send operation becomes synchronous. However generally it is not good idea to make synchronous calls in terms of efficiency.- When the send method is called producer serializes the key and value to
ByteArrays, so that they can be sent over the network. - After serialization, partitioner calculates the partition to be sent according to provided key. If no key is provided it will select with round robin. Partitioner calculates a hash of the key by default using
MurmurHashalgorithm and uses the following formula to get the partition:
Utils.abs(Utils.murmur2(record.key())) % numPartitions;So note that if number of partitions change later, the same key -> same partition guarantee no longer holds for the previous calculations.
- Producer contains a pool of
buffer. Records are first added to buffer. This is used to gather number of records and send as batch to increase the efficiency. - Producer has a separate thread that reads the records from buffer and sends to cluster.
So these are the important features of the producers. By using more of configurations we can control the behaviour of a producer. Now I will list the important configurations of the producers that we can set at the properties object.
Producer Acks
Replication-factor species the total number of copies of a partition (Leader + In-Sync Replicas). When producer sends records to Kafka it sends records to only the leader of the partition and leader sends syncs to in-sync replicas. So acks configuration is about how many copies of partition should receive the data before producer can say that sending record is successfully done.
acks=0: Producer will not wait for any acknowledgment from the server at all. If broker goes down or in case of any other problem we will end up losing the data. On the other hand we can achieve achieve very high throughput. We can use if we can tolarate the data loss.acks=1: Producer will only wait the Leader to write the data to its logs. This is the default. In this case if Leader goes down before sharing syncs to other replicas data will be lost.acks=allProducer will wait until all replicas receives the data. Leader will wait all replicas to send acknowledgment and then it will send ack to the producer. This adds safety but also latency. We can use if we can not tolarate the data loss.
Note that all replicas is bounded by the broker or topic's min.insync.replica configuration. It can be configured in at Topic or Broker level not at the Producer level. For example if we have replication.factor=3, min.insync.replica=2 and acks=all then Producer will wait 2 replicas to ack that they received the data.
Producer Retries
retries: if producer receives error after sending the data, for example an error related to acks then it can automatically retries to send the record. Therefore ifacks=0retries config will not be effective. Default value is set toInteger.MAX. So it can retry many time.retry.backoff.ms: config sets the time to wait before attempting another retry and by default it is set to100 ms.delivery.timeout.ms: Producer won't retry forever. It's bounded by a timeout. Default value is120 000 ms== 2 mins.
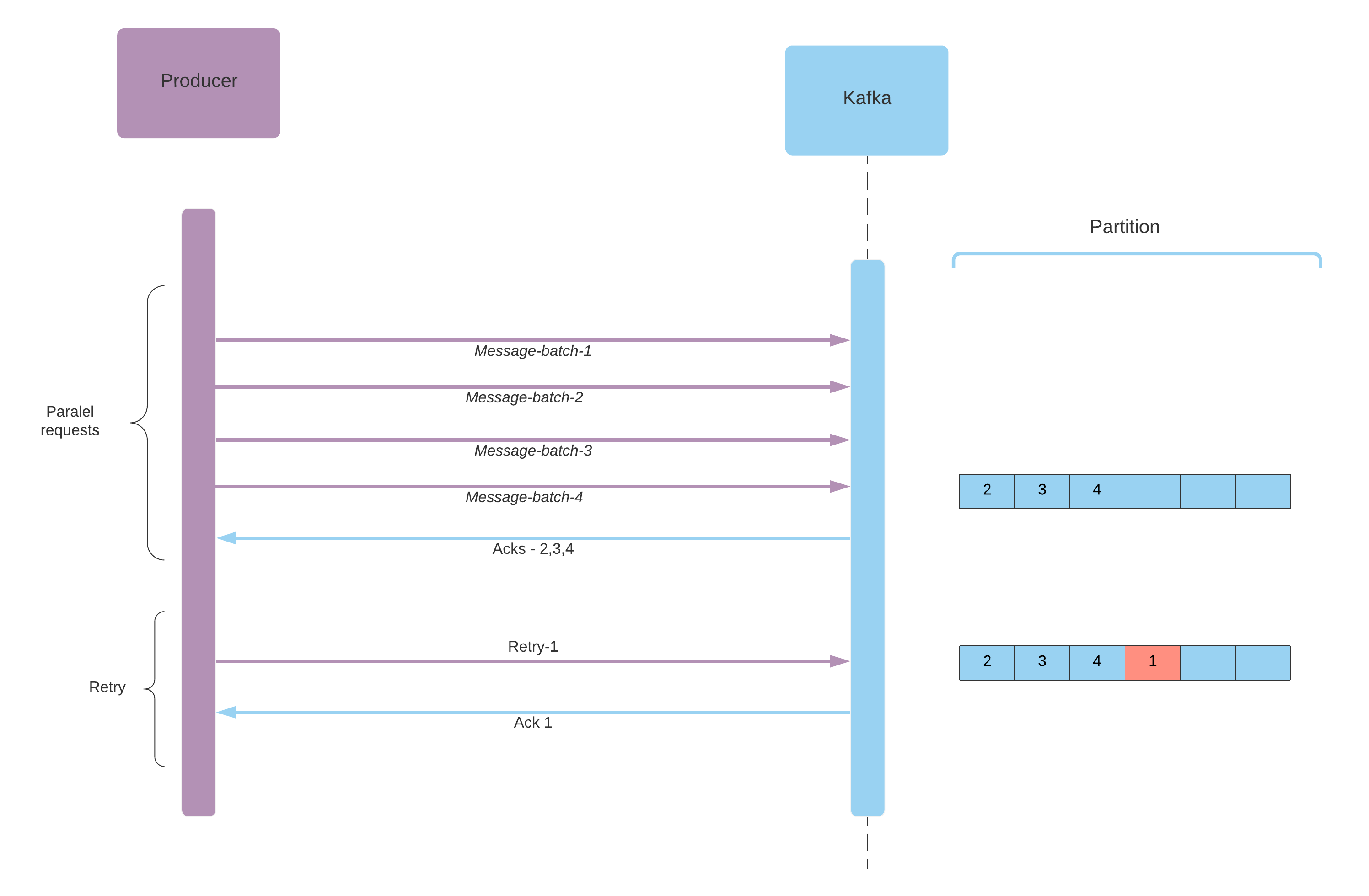
Note that when a retry occurs there is a chance that records will be out of order. If you rely on key based ordering this could be a problem. In order to guarantee that message ordering will remain the same, we can limit the number of parallel requests from producer with the following config. Of course decreasing this number impacts the throughput.
max.in.flight.requests.per.connection: The maximum number of unacknowledged requests the client will send on a single connection before blocking. Default value is5. Set to 1 if you need to ensure the ordering.
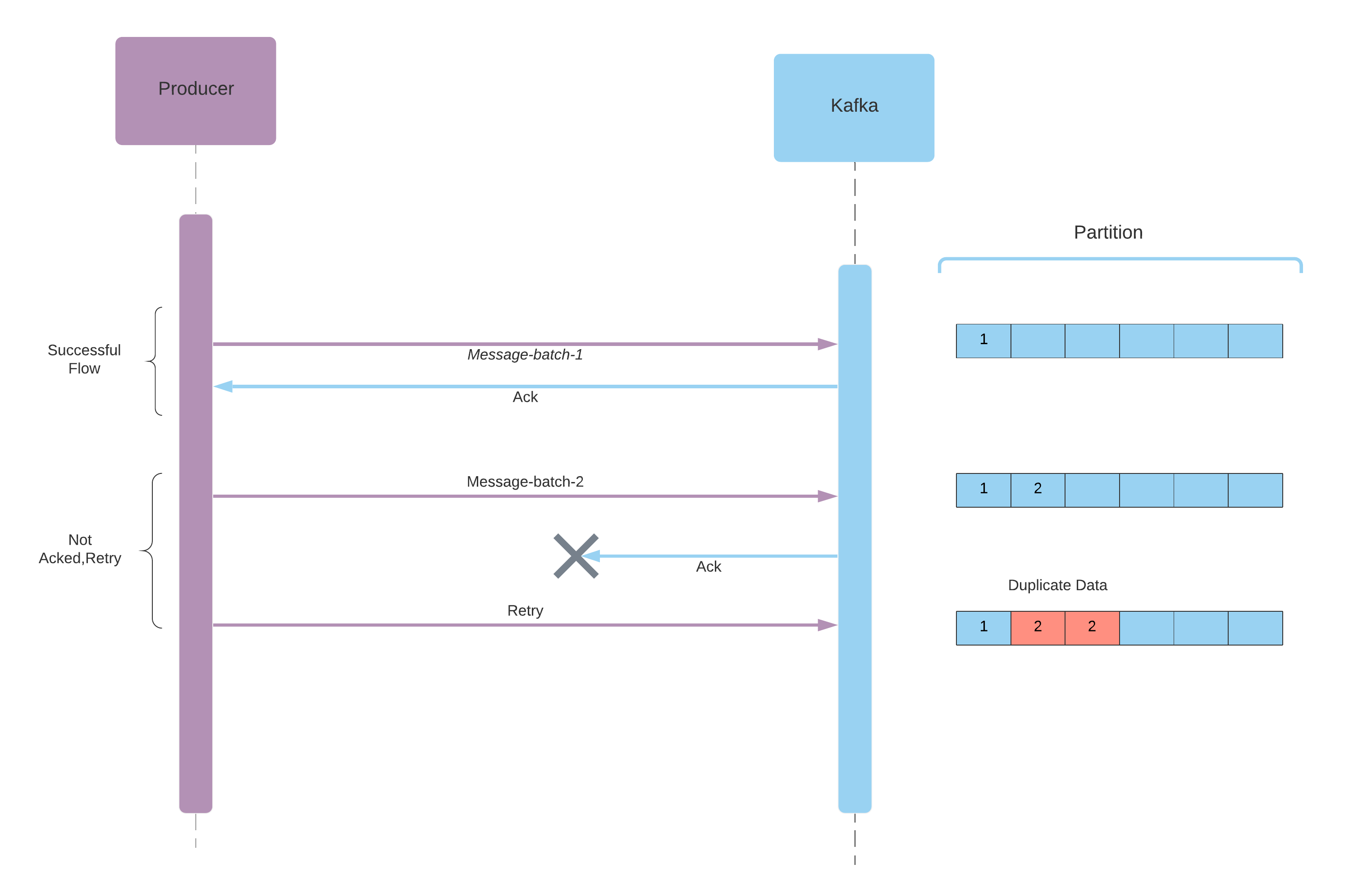
Producer delivery semantics might be confusing, and they are case dependent. And there is also another problem regarding these configs, we may end up with duplicate data. To solve these problems there is an alternative and very nice solution: Idomponent Producer.
Idempotent Producer
Idempotent producers address the following problems:
- When a retry occurs (data is not saved correctly), the ordering of the batches may change because in the meantime there might possibly be parallel requests from Producer that is saving other data.
- When the data is saved but Ack is not received, then producer retries and it causes duplicate records.
Idempotent producers provides us safe and stable pipelines with exactly once delivery semantic. They come automatically with the following configuration by default:
acks= allretries= Integer.MAXmax.inflight.requests= 5
Parallel requests are allowed but ordering is guaranteed as well. So how to make a producer idempotent? Well it is so easy by setting the following configuration property:
enable.idempotence = true
Idempotence guarantees are added with introducing producer ID and sequence number for messages. These implementations are not exposed to users. For each message, the sequence number is incremented and this number is being tracked to provide the order and duplicate detection. If you would like to look into details of implementation see the Kafka-5494.
Producer Compression
Compressing the batch messages provides smaller request size, faster transfer, better throughput so it increases efficiency but on the other hand it adds a small compression overhead. Compression should be enable at Consumer level and does not require any configuration at Broker or Consumer level.It is more effective if the when we have bigger batches. It can be set by the configuration property compression.type :none, gzip, lz4 or snappy.
Producer Batching
By default Kafka tries to send message asap. Message sending at the same time is bounded with. max.inflight.requests. If there is more than max allowed it is batched and send later. The following parameters can be used to configure batching behaviour of the producer:
linger.ms: Number of mili seconds the producer waits before sending a batch. Default value is zero. So it sends immediately. But setting this number to get a small delay creates a chance to batch the messages. For example we can set 10-20 ms.
batch.size: It is a size bound for a batch to be send. If batch size reaches this limit it is sent.
Safe Producer
Given the above configuration properties best way to achieve a safe producer seems to use an idempotent producer. Idempotent Producer automatically adds the configurations for acks, retries and max in-flight requests but it can be added to increase the readability of the code, and to give hint to the readers of your code.
Properties properties = new Properties();
// obligatory
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// idempotent
properties.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
// automatically added for an idempotent producer
properties.setProperty(ProducerConfig.ACKS_CONFIG, "all");
properties.setProperty(ProducerConfig.RETRIES_CONFIG, String.valueOf(Integer.MAX_VALUE));
properties.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, "5");
KafkaProducer <String, String> producer = new KafkaProducer <>(properties);High Throughput Producer
To increase the throughput we can add linger.ms to increase the batching likelihood, enable batch compression with compression.type, and increase the batch.size.
properties.setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "20");
properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, Integer.toString(32*1024)); // 32 kbReferences
- Narkhede, N., Shapira, G., & Palino, T. (2017). Kafka: The definitive guide: Real-time data and stream processing at scale. Sebastopol, CA: O'Reilly Media.

