
Apache Kafka Advanced Consumers
In order to read data from the Kafka cluster, we use the generic KafkaConsumer<K, V> class that helps us to subscribe to a topic and receive messages from the topic.
Before getting into Kafka Consumer it is important to understand the basics of the Kafka and especially the consumer groups and partition rebalance concepts. See the Apache Kafka Basics
I will start with showing the basic implementation of Kafka Consumer and then discuss the details of configurations.
Basic Kafka Consumer Implementation
- Add
kafka-clientsDependency:
compile 'org.apache.kafka:kafka-clients:2.5.0'- Create Properties
KafkaConsumer<K, V> class needs a Properties object to be able to create a new instance. So we can create a Java Properties object and add the initial configuration properties.
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "myConsumerGroup-1");
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");Note that we added group.id config to specify the consumer group, and also auto.offset.reset config to specify that initially we would like to start reading from earliest offset. Later on our consumer's last read offset will be saved and used.
- Create Consumer
With using our properties we can initiate our consumer. We need to specify the types of Key and Value to the generic KafkaConsumer class. Simply we can use String keys and values if messages does not have a schema.
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);- Subscribe to a topic
consumer.subscribe(Collections.singletonList("topic"));Alternatively we can subscribe with a regex Pattern to all matching topics:
consumer.subscribe("location.*");- Read the records in a loop
while (true) {
ConsumerRecords <String, String> records = consumer.poll(Duration.ofMillis(200));
records.forEach(record -> System.out.println(record.toString()));
}This step needs attention. There is an infinite loop for consumer to continually poll the records. Kafka client developers documented that only safe way to break this loop is using the consumer.wakeup() method. Method makes the consumer to throw WakeupException and it leaves the while loop. It is a checked exception and should be handled by the listener.
- Close consumer
Remember closing the consumer gracefully when you no longer need or application exits. Failure to close the consumer will leak the resources that it is using.
consumer.close();Putting Pieces Together
public class Consumer {
private final static Logger logger = LoggerFactory.getLogger(Consumer.class);
private final KafkaConsumer<String, String> consumer;
private final ExecutorService executor;
private final CountDownLatch latch;
public Consumer() {
consumer = new KafkaConsumer <>(getDefaultProperties());
latch = new CountDownLatch(1);
executor = Executors.newSingleThreadExecutor();
}
private Properties getDefaultProperties() {
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "myConsumerGroup-0");
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return properties;
}
public void startListening(String topic) {
logger.info("Starts Listen Task");
executor.submit(getListenTask(topic));
}
private Runnable getListenTask(String topic) {
return () -> {
addShutDownHook();
consumer.subscribe(Collections.singletonList(topic));
try {
while (true) {
pollRecords();
}
} catch (WakeupException ex) {
logger.error("Wake up received");
} finally {
consumer.close();
logger.info("consumer is closed");
latch.countDown();
}
};
}
private void pollRecords() {
logger.info("polling");
ConsumerRecords <String, String> records = consumer.poll(Duration.ofMillis(200));
records.forEach(record -> logger.info(record.toString()));
}
private void addShutDownHook() {
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
logger.info("Shutdown is caught");
stopConsumer();
closeExecutor();
}));
}
public void stopConsumer() {
consumer.wakeup();
try {
latch.await();
} catch (InterruptedException e) {
logger.error("Barrier wait is interrupted");
}
}
public void closeExecutor() {
executor.shutdownNow();
try {
executor.awaitTermination(5, TimeUnit.SECONDS);
} catch (InterruptedException e) {
logger.error("Could not shutdown executor");
executor.shutdownNow();
Thread.currentThread().interrupt();
}
}
}Note that with the shutdown hook that will be caught on exit, or implicitly by calling the stopConsumer method we introduce wakeup and WakeupException breaks the while loop.
KafkaConsumer is not thread safe and you can’t have multiple threads safely using the same consumer unless you handle concurrency by yourself. One consumer per thread is the rule. To run multiple consumers in the same group in one application, it is better idea to run each in its own thread. That is why we are running it on a separate thread by executor service. Another point for our example is that it is not a good idea to block our main thread with infinite loop.
Consumer Delivery Semantics
Kafka consumers keep track of their position for the partitions. Each time poll() method is called, Kafka returns the records that has not been read yet, starting from the position of the consumer.
Consumers are responsible to commit their last read position. Consumers use a special Kafka topic for this purpose: __consumer_offsets. If consumer goes down and turn back or a new consumer joins to group, rebalancing occurs and partitions might be assigned to different consumer. In that case, consumer uses the last commit offset in order to know where to pick up the work.
Therefore, after some records received after polling, consumer has to commit its offset. It can be done in different ways:
At most once: Offsets are committed as soon as the message is received. If the processing goes wrong, the message will be lost.
At least once: Offsets are committed after the message is processed. If the processing goes wrong, the message will be read again. This results in duplicate processing of messages, if duplicate processing does not impact our system, it can be used. This is the default behaviour.
Exactly once: Can be achieved for Kafka to Kafka workflows.
Auto Commit
KafkaConsumer has enable.auto.commit configuration that is by default set to true. Having this configuration consumer commits the largest offset every 5 seconds. This duration is specified by the configuration auto.commit.interval.ms. Bear in mind that auto-commit is driven by poll method, on each invocation it checks if it is time to commit.
Automatic commits are convenient, and can be used if processing the same data multiple times does not impact our system. But they don’t give developers enough control to avoid duplicate messages. Another problem with auto committing is that if processing the received data is done asynchronously, then loop will immediately turn back to beginning and offsets will be committed already without know how the processing goes. So in this case it behaves as at most once, and our data will be lost if processing fails.
Manual Commits
Generally having the control over the commits is preferred way in order to eliminate duplicates or lost data. The consumer API exposes commit methods to let the developer decide committing offset at a point that makes sense, rather than making based on a timer.
By setting auto.commit.offset=false, offsets will be only committed when the application explicitly chooses to do so. We can commit by either sync or async methods:
public void commitSync();This method will commit the latest offset returned by poll() and return once the offset is committed, throwing an exception if commit fails for some reason. So we should use it after we are done with processing.
One of the advantage of commitSync method is that it retries committing automatically as long as there is no error that can’t be recovered. If there is an unrecoverable error happens, there is not much we can do except log an error.
while (true) {
logger.info("polling");
ConsumerRecords <String, String> records = consumer.poll(Duration.ofMillis(200));
records.forEach(record -> logger.info(record.toString()));
try {
consumer.commitSync();
} catch (CommitFailedException ex) {
logger.error("Commit failed with exception: {}", ex);
}
}Drawback of the synchronous committing is that our thread gets blocked until the commit operation is finished. This indeed decreases our throughput. Second option to commit manually is committing asynchronously.
public void commitAsync();
// or with a callback
public void commitAsync(OffsetCommitCallback callback);The drawback of async commits is that it does not retry to commit if some error occurs. It actually chooses to not retry committing because of a reason. If the problem is temporary, other poll invocations already commits higher offset numbers. So if our failed commit retries to push the offset then it overrides the already committed offsets. See the figure to understand such a behaviour:
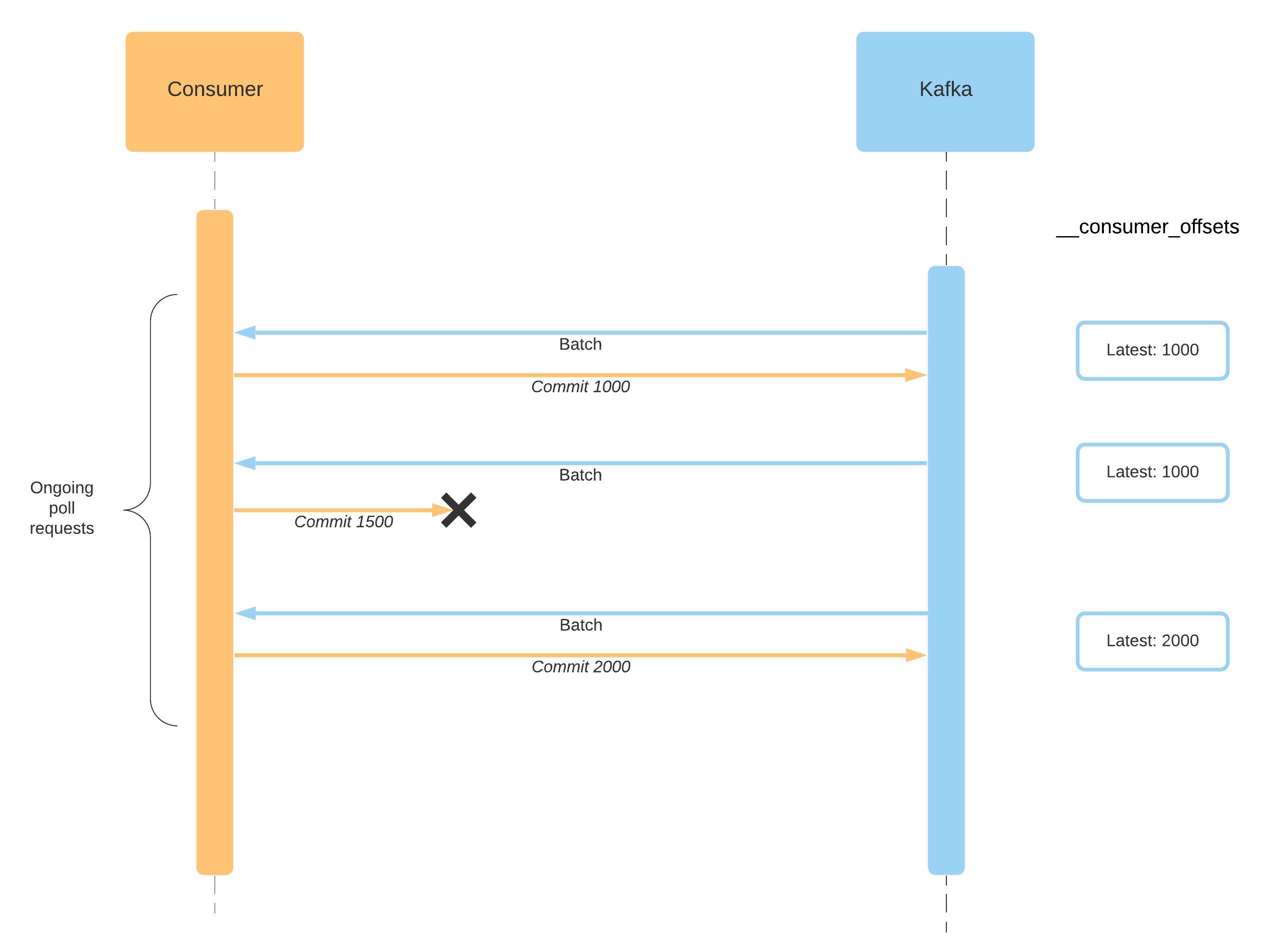
When Commit 1500 fails, it does not retry to commit, latest position remains unchanged. In the meantime Commit 2000 succeeds and latest position becomes 2000. So if async commits were to retry failed commits it would override the latest committed one which is 2000 and position would become 1500 which is not correct and results in duplicate processing.
Combining Async and Sync Commits
Async commits increases our throughput but on the other hand there might be cases that we need to guarantee that delivery is done successfully. For example before closing the application we would like to make sure that our last commit is delivered successfully. So for such cases we can use synchronous commits.
try {
while (true) {
logger.info("polling");
ConsumerRecords <String, String> records = consumer.poll(Duration.ofMillis(200));
records.forEach(record -> logger.info(record.toString()));
consumer.commitAsync((offsets, exception) -> {
if (exception != null) {
logger.error("Commit failed for offests: {} with the exception: {}",
offsets.toString(), exception.getMessage());
}
});
}
} catch (WakeupException ex) {
logger.error("Wake up received");
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
logger.info("consumer is closed");
latch.countDown();
}
}So for a normal usage we use async but when we are closing we want to make sure it will. be retried to commit until it is successfully saved.
Reprocessing the Data
Consumer API provides few useful methods that can be used to change the consumer's position for an earlier offset and repeat the processing.
Position Method
public long position(TopicPartition partition);Get the offset of the next record that will be fetched.
Seek Methods
// Overrides the fetch offsets that the consumer will use on the next poll
public void seek(TopicPartition partition, long offset);
// Seek to the first offset for each of the given partitions.
public void seekToBeginning(java.util.Collection<TopicPartition> partitions);
// Seek to the last offset for each of the given partitions.
public void seekToEnd(java.util.Collection<TopicPartition> partitions);-
Assign Methods
// Manually assign a list of partitions to this consumer
public void assign(java.util.Collection<TopicPartition> partitions)Note that manual partition assignments should be done carefully. Manual topic assignment through this method does not use the consumer's group management functionality. As such, there will be no rebalance operation triggered when group membership or cluster and topic metadata change. So in case of a simple reprocessing we can unset group id, which assigns a random group id and we can process. By this way we will not affect the group coordination.
Rebalance Listener
When consumer group members are changed, for instance a new consumer joins or one consumer goes down, group coordinator makes a partition rebalancing. The consumer API provides the ability to listen rebalance events. So we can run do some cleanup, for example committing the offsets closing I/O connections before partition is removed from a consumer, or we can run some init task when a new consumer gets a partition assigned. In order to add partition listener, we need create an instance of ConsumerRebalanceListener class. It has following 2 methods to override:
public void onPartitionsAssigned(Collection<TopicPartition> partitions);
public void onPartitionsRevoked(Collection<TopicPartition> partitions);The following example explains storing the commit offsets in extarnal store such as database:
public class SaveOffsetsOnRebalance implements ConsumerRebalanceListener {
private Consumer<?,?> consumer;
public SaveOffsetsOnRebalance(Consumer<?,?> consumer) {
this.consumer = consumer;
}
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// save the offsets in an external store using some custom code not described here
for(TopicPartition partition: partitions)
saveOffsetInExternalStore(consumer.position(partition));
}
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// read the offsets from an external store using some custom code not described here
for(TopicPartition partition: partitions)
consumer.seek(partition, readOffsetFromExternalStore(partition));
}
}References
- Narkhede, N., Shapira, G., & Palino, T. (2017). Kafka: The definitive guide: Real-time data and stream processing at scale. Sebastopol, CA: O'Reilly Media.

