
Kafka Connect Basics
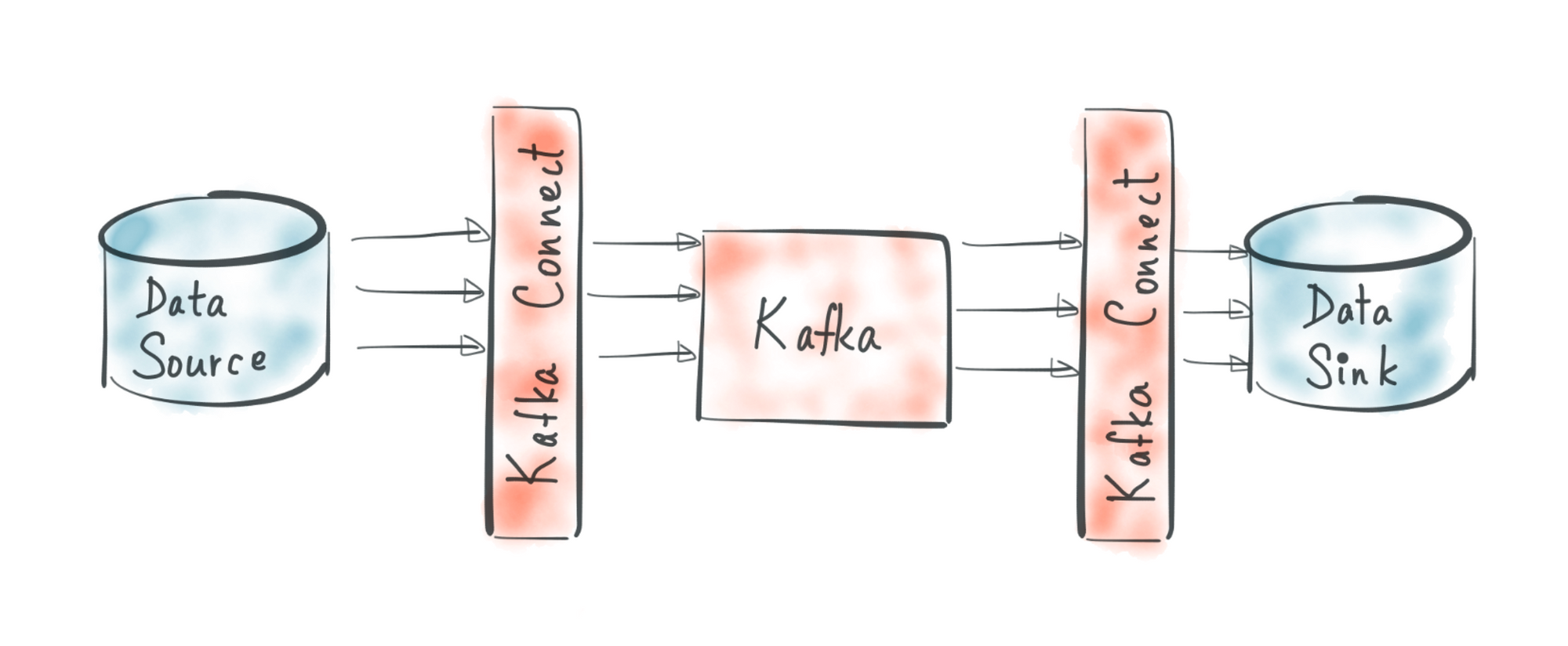
Kafka Connect is an open source Apache Kafka component that helps to move the data IN or OUT of Kafka easily. It provides a scalable, reliable, and simpler way to move the data between Kafka and other data sources. According to direction of the data moved, the connector is classified as:
Source Connector: Reads data from a datasource and writes to Kafka topic.Sink Connector: Reads data from Kafka topic and writes to a datasource.
Kafka Connect uses connector plugins that are community developed libraries to provide most common data movement cases. Mostly developers need to implement migration between same data sources, such as PostgreSQL, MySQL, Cassandra, MongoDB, Redis, JDBC, FTP, MQTT, Couchbase, REST API, S3, ElasticSearch. Kafka plugins provides the standardised implementation for moving the data from those datastores. Find all available Kafka Connectors on Confluent Hub.
So what Kafka Connect provides is that rather than writing our own Consumer or Producer code, we can use a Connector that takes care of all the implementation details such as fault tolerance, delivery semantics, ordering etc. and get the data moved. For example we can move all of the data from Postgres database to Kafka and from Kafka to ElasticSearch without writing code. It makes it easy for non-experienced developers to get the data in or out of Kafka reliably.
Concepts
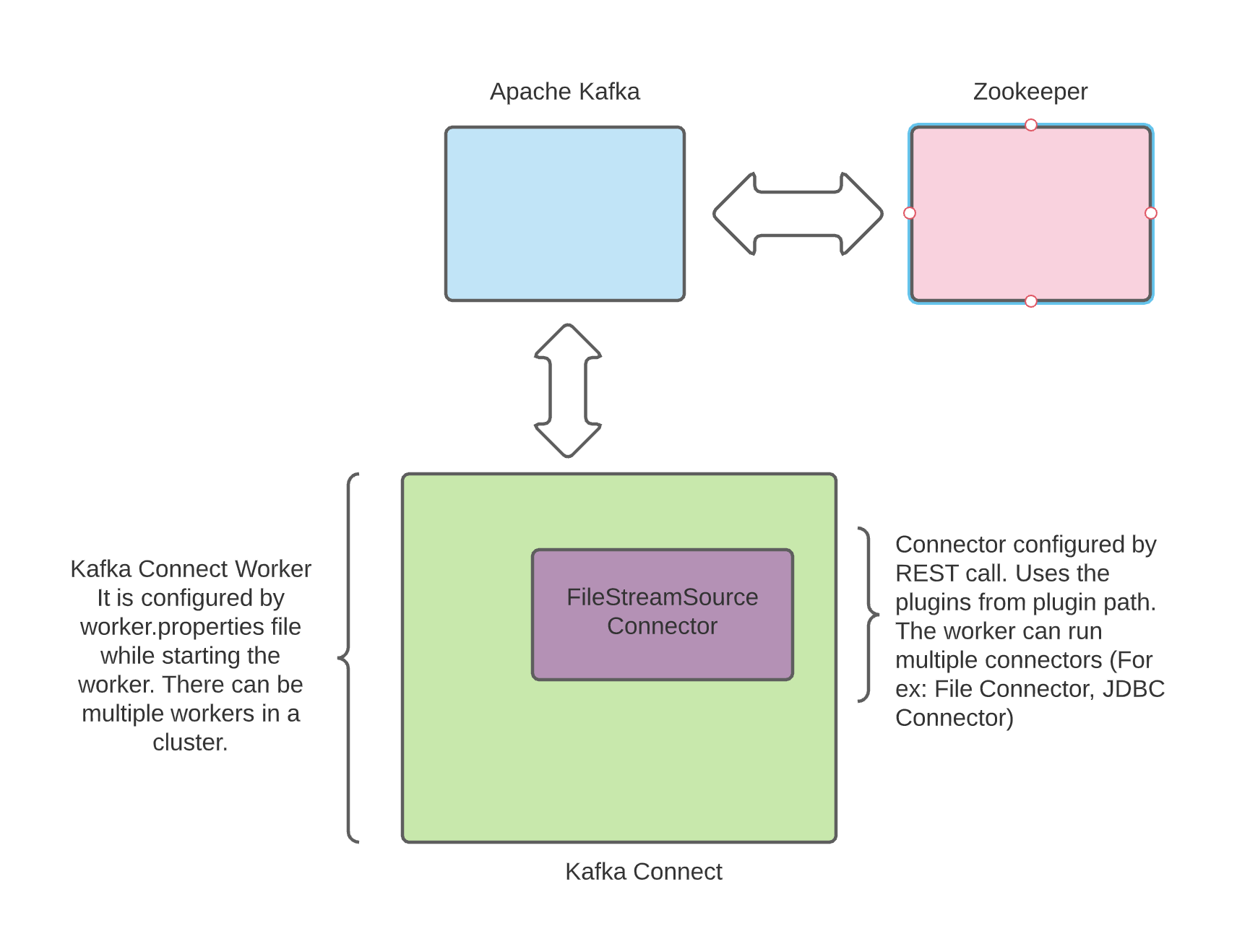
Connector plugins implement the connector API that includes connectors and tasks.
Connector: is a job that manages and coordinates the tasks. It decides how to split the data-copying work between the tasks.Task: is piece of work that provides service to accomplish actual job.
Connectors divide the actual job into smaller pieces as tasks in order to have the ability to scalability and fault tolerance. The state of the tasks is stored in special Kafka topics, and it is configured with offset.storage.topic, config.storage.topic and status.storage.topic. As the task does not keep its state it can be started, stopped and restarted at any time or nodes.
For example JDBC Connector is used to copy data from databases and it creates task per each table in the database.
Worker: is the node that is running the connector and its tasks.
Kafka Connect workers executes 2 types of working modes:
Standalone mode: All work is performed in a single worker as single process. It is easier to setup and configure and can be useful where using single worker makes sense. However it does not provide fault tolerance or scalability.Distributed mode: Multiple workers are in a cluster. Configured by REST API. Provides scalability and fault tolerance. When one connector dies, its tasks are redistributed by rebalance mechanism among other workers.
Running Kafka Connect
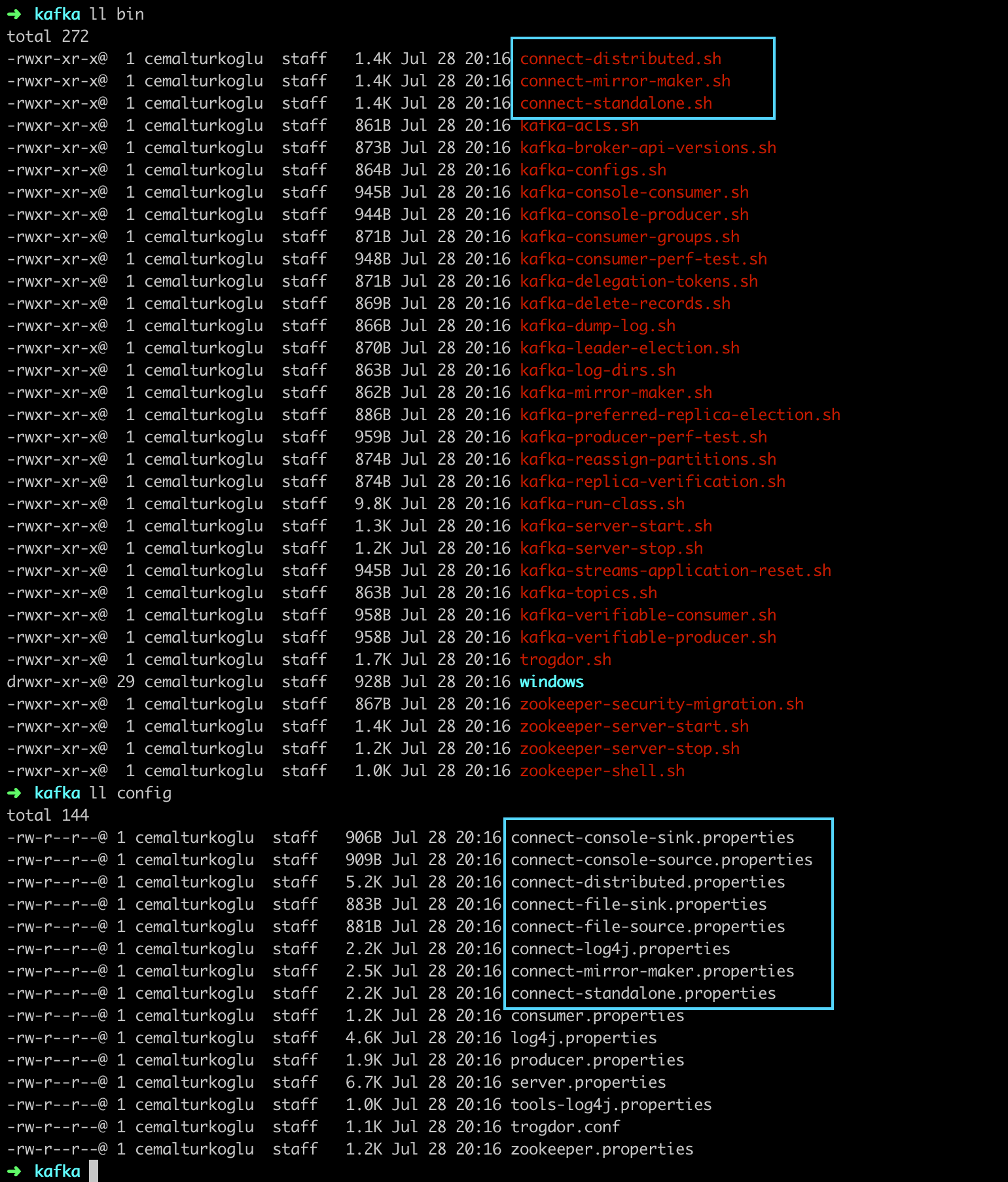
Kafka Connect ships with Apache Kafka binaries. So there is no need to install it separately, but in order to run it we need to download Kafka binaries. The executables are in the bin directory and configurations are in the config directory.
I personally would prefer you to start practising with distributed mode as it is gets unnecessarily confusing if you work with the standalone and after switch to distributed mode. Also it is recommended to use distributed mode in production, and if we don't want to have a cluster we can run only 1 worker in distributed mode.
1 - Running Kafka Cluster
Let's start with getting a Kafka cluster up and running. We can set up a cluster with one zookepeer and one broker in docker environment with using the following docker compose file.
version: '2'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: confluentinc/cp-kafka:latest
hostname: kafka
container_name: kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1Run the docker-compose up -d command to start the containers. One thing to pay attention here is that KAFKA_ADVERTISED_LISTENERS are set to be localhost:29092 for outside of docker network, and kafka:9092 for inside the docker network. So from out host machine we can access kafka instance with localhost:29092.
2 - Running Kafka Connect
We can run the Kafka Connect with connect-distributed.sh script that is located inside the kafka bin directory. We need to provide a properties file while running this script for configuring the worker properties.
connect-distributed.sh <worker properties file>We can create create connect-distributed.properties file to specify the worker properties as follows:
# A list of host/port pairs to use for establishing the initial connection to the Kafka cluster.
bootstrap.servers=localhost:29092
# unique name for the cluster, used in forming the Connect cluster group. Note that this must not conflict with consumer group IDs
group.id=connect-cluster
# The converters specify the format of data in Kafka and how to translate it into Connect data.
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# Topic to use for storing offsets. This topic should have many partitions and be replicated and compacted.
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
# Topic to use for storing connector and task configurations; note that this should be a single partition, highly replicated,
config.storage.topic=connect-configs
config.storage.replication.factor=1
# Topic to use for storing statuses. This topic can have multiple partitions and should be replicated and compacted.
status.storage.topic=connect-status
status.storage.replication.factor=1
# Flush much faster than normal, which is useful for testing/debugging
offset.flush.interval.ms=10000group.id is one of the most important configuration in this file. Worker groups are created according to group id. So if we start multiple worker with same group id, they will be in the same worker cluster.
offset.storage.topic, config.storage.topic and status.storage.topic configurations are also needed so that worker status will be stored in Kafka topics and new workers or restarted workers will be managed accordingly.
Now we can start Kafka connect with the following command:
connect-distributed.sh /path-to-config/connect-distributed.properties3 - Starting Connector
Now we have Zookeeper, Kafka broker, and Kafka Connect running in distributed mode. As it is mentioned before, in distributed mode, connectors are manages by REST API. Our connector exposed REST API at http://localhost:8083/.
As an example, we can run a FileStreamSource connector that copies data from a file to Kafka topic. To start a connector we need to send a POST call to http://localhost:8083/connectors endpoint with the configuration of the Connector that we want to run. Example configuration for Connector looks like as follows:
{
"name": "local-file-source",
"config": {
"connector.class": "FileStreamSource",
"tasks.max": 1,
"file": "/Users/cemalturkoglu/kafka/shared-folder/file.txt",
"topic": "file.content"
}
}
Every connector may have its own specific configurations, and these configurations can be found in the connector's Confluent Hub page.
connector.classspecifies the connector plugin that we want to use.fileis a specific config forFileStreamSourceplugin, and it is used to point the file to be read.topicis the name of the topic that the data read from file will be written to.
We need to send this json config in the content body of REST call. We can read this config from file for curl command as follows:
curl -d @"connect-file-source.json" \
-H "Content-Type: application/json" \
-X POST http://localhost:8083/connectorsAfter this call connector starts running, it reads data from the file and send to the kafka topic which is file.content in the example. If we start a consumer to this topic:

We can see that every line in the file.txt is send to Kafka topic as a message. Note that key.converter.schemas.enable and value.converter.schemas.enable is set to be true for the worker at the beginning. So messages are wrapped with Json schema.
In order to scale up the worker cluster, you need to follow the same steps of running Kafka Connect and starting Connector on each worker (All workers should have same group id). The high level overview of the architecture looks like as follows:
Running Kafka Connect in Docker
In the above example Kafka cluster was being run in Docker but we started the Kafka Connect in the host machine with Kafka binaries. If you wish to run Kafka Connect in Docker container as well, you need a linux image that has Java 8 installed and you can download the Kafka and use connect-distribued.sh script to run it. For a very simple example, you can use the following Dockerfile to run workers:
FROM openjdk:8-jre-slim
RUN apt-get update && \
apt-get install wget -y
COPY start.sh start.sh
COPY connect-distributed.properties connect-distributed.properties
RUN echo "Downloading Apache Kafka" && \
wget "http://ftp.man.poznan.pl/apache/kafka/2.6.0/kafka_2.12-2.6.0.tgz" &&\
tar -xzvf kafka*.tgz && \
rm kafka*.tgz && \
mv kafka* kafka && \
export PATH="$PATH:$(pwd)kafka/bin"
CMD /kafka/bin/connect-distributed.sh connect-distributed.propertiesYou can customise the Dockerfile according to your needs and improve it or you can use Confluent's Kafka Connect image by adding it to the docker-compose file as follows:
connect:
image: confluentinc/cp-kafka-connect:latest
hostname: connect
container_name: connect
depends_on:
- zookeeper
- kafka
ports:
- "8083:8083"
volumes:
- ./shared-folder:/shared-folder
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka:9092
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_REST_PORT: 8083
CONNECT_GROUP_ID: compose-connect-group
CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000
CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_INTERNAL_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_INTERNAL_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_ZOOKEEPER_CONNECT: zookeeper:2181
CONNECT_PLUGIN_PATH: /usr/share/java
